
|
Tuesday, May 06, 2008
Having already motivated this series, I'll provide the first example of how to put your time to more productive use than participating in the WikiProject G.I. Joe or the still more urgent WikiProject Transformers. If you get interesting results, post them on your blog and provide a link in the comments here. I'll gather up all the results after awhile and summarize them in a follow-up post.
Purpose Cultural transmission has often been described verbally as viral. Mathematical models of culture incorporate this idea by borrowing epidemic disease models from biology. The goal here is to see if data on "viral videos" support the infectious model of culture. Pre-requisites To collect and analyze data: high school algebra, including familiarity with exponentials and logarithms. To get the theory behind the model: first-semester calculus and preferably an understanding of phase plane methods to study a two-variable system of ordinary differenital equations. [1] No knowledge of biology or culture is needed. Details Edelstein-Keshet's Mathematical Models in Biology (pp. 242 - 254) provides a good overview of the most basic models of epidemic diseases, and that's what I'm adapting here. In brief, we track the growth rates of two or three classes of hosts: Susceptibles (S), Infectives (I), and perhaps Recovereds (R). The names mean what you think. In the case of viral videos, you can never undo having seen the video, so we will use a very simple model, illustrated below: 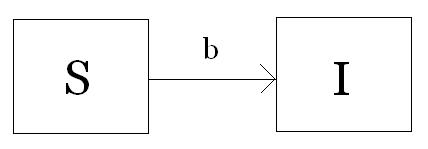 If you haven't seen the video yet, you're Susceptible, while if you have seen it, you're Infective. The idea is that someone who's seen the video tells their friends about it in some way, and their friends watch it in their turn. A Susceptible is turned into an Infective at a rate b, so that this parameter measures the infectivity of the video. We ignore the part of the population that has immunity to the video -- perhaps because they are not in the target demographic group -- and only track those who could be or are infected. We also assume that on the time-scale that the video spreads, the population is constant in size, which seems realistic in this case. We can write down a system of differential equations for the above picture: dS / dt = - bSI dI / dt = bSI (The product SI is used as an analogy with chemistry's law of mass action for particles that knock into or interact with each other.) We notice that dS / dt + dI / dt = 0, which means that S + I = constant, call it N. In other words, if we know the number of Infectives, we automatically know the number of Susceptibles -- it is just N - I. Therefore, we don't have to keep a separate tally of the change in S and can eliminate the first equation. Subsituting S = N - I into the second equation, our system becomes just: dI / dt = bI(N - I) Let's make a natural change of variables: i = I / N g = bN So, i is the fraction of the population that is Infective, and the growth rate g has units of inverse time (where b had units of 1 / (people * time)). The equation now only has one variable and one parameter: di / dt = gi(1 - i) This is the famous logistic equation, which you may already have seen in the context of saturating population growth or the spread of a favored allele to fixation. (The analogies between these three processes are reflected in their being modeled by the same equation, which underscores the importance of formalizing your intuition.) At equilibrium, the fraction that is Infective does not change, so di / dt = 0. This happens when either i = 0 or i = 1. When i is between 0 and 1, di / dt is positive, so as long as i is not exactly 0, i will increase as time increases and will ultimately end up at i = 1. In other words, i = 0 is an unstable steady-state since a small increase will push it to i = 1, which is stable. This model may seem simplistic since it implies that every single Susceptible will be eventually see the video, but that's not so unrealistic when you recall that we're only considering the population of the video's target audience -- in 1993, how many teenagers who had TVs in their homes never, ever saw that Blind Melon video with the bee girl? Some videos may have larger or smaller target audiences, i.e. larger or smaller values of the parameter N. Getting and Analyzing Data It is impractical for someone without the funding to survey a large random sample of the target audience to attempt to do so. Therefore, we would measure a good enough proxy: the view count for a YouTube video, tracked over time. Depending on how rapidly you think it will increase, you may want to measure it every 6 hours, or once a day. If it grows logistically, it should accelerate first and then still increase but decelerate until it more or less plateaus, like this the picture in the Wikipedia page on the logistic function. Ideally, you want to track a video that is the only one of its kind -- if there are multiple copies of the same video, that complicates things somewhat, but you might ignore that (see Further Avenues). For example, if a YouTube celebrity is able to curb reproductions of their videos, you can simply wait until their channel puts out a new video. The infectious process would go something like, "Omigod, So-and-So just put out a new video -- you have to see it!" This would be easier if they update fairly infrequently, so that word-of-mouth transmission were the primary route of infection. Another idea is to wait for the music video of a popular song to come out, but this requires that you be pretty savvy about music trends, and here the potential of multiple copies is even more serious, as fans download it and upload it themselves. Fad news items are another source, like when that retarded brat got tasered in the UCLA library. Again, multiple copies of it will probably appear. Assuming you got something like logistic growth, here's how you estimate the parameters N and b. Well, N would just be whatever the plateau value seems to be, so you'll have to wait for it to do so first. It can be shown that the solution to the logistic equation can be re-arranged to yield: ln ((N - I) / I) = - bt + ln ((N - I0) / I0) Where N is the max view count, I0 is the initial view count -- pick some small number -- I is the view count at time t, and b is the infectivity rate. So after you've got a concrete number for N and I0, you'd plot (N - I) / I on a ln scale -- it will be a linear function of t, with y-intercept = ln ((N - I0) / I0) and slope = - b. See what b turns out to be. Then compare values of N and b for different videos. If N is larger for one, that means the target audience is larger (ignoring the fact that a single person may watch a given video multiple times -- that's true for any video, no matter the target audience's size). If b is larger for one, that means it's more infectious. Further Avenues If you really kept this going long-term, you could try to classify the videos you're tracking by category and do an analysis of variance or something to see what accounts for the variation in the target audience size and in the infectiousness of a video. Intuitively, we expect more sensational videos to have higher b -- but a hard analysis might tell us more concretely what types of things count as more sensational. We have guesses about that, but we need data to see if those guesses are right. To make the model a bit more complex, you could introduce a stochastic component to the growth equation. Right now, it is deterministic: as long as the ball gets rolling, everyone in the target audience will see the video. But when few people have seen the video, chance effects could push one ball up while letting another ball stay put. This is like when several copies of a favored allele are introduced into a population -- some will be lost by drift, while another may be propelled quickly by drift at the start, after which point the deterministic equations take over. You would model it just like the frequency of a favored allele under the combined effects of drift and directional selection. In the context of viral videos, consider multiple copies of the same music video (again due to fans downloading the video from the official channel and uploading it to their own channel). As the target audience does a search for this video, chance effects may propel one of the copies up very quickly while letting other copies languish with low view counts. In this case, the copy that ends up dominating the market increases even more rapidly than under the purely deterministic model because it got a lucky big initial boost through sheer chance effects. This is what makes is somewhat inappropriate to compare a video that only has one copy to see vs. a video with multiple copies to see. The winner in the latter group will appear more infectious than the former, since it increases much faster, but part of that higher increase is accounted for by chance. [1] MIT's Open CourseWare site has a great mathematics section that allows you to teach yourself or brush up on these areas. Especially useful is the course on differential equations, which has a full set of video lectures, solved problem sets, exams, and helpful Java applets. An easy to use phase plane applet is pplane. Labels: do it yourself studies
Monday, May 05, 2008
Get off your ass and do this study: Introductory pep talk
posted by
agnostic @ 5/05/2008 01:19:00 PM
I was recently directed to this panegyric on Wikipedia, which claims that editing Wikipedia is a better use of the cognitive surplus that might otherwise be spent watching TV. Like 99% of technology pundits, the author is so out of touch with reality that it is not worth taking him to task in depth. Instead, reading that has moved me to begin a regular column wherein I propose a fairly simple study for someone to carry out and increase our understanding of the world.
In fairness, it is often tough to think of a study to do, or how you would concretely carry it out. But since my soul is a font of generosity, I'm literally giving ideas away. We only have so much time and effort to invest in a project, so I have plenty of ideas that I just don't have time to pursue in any depth. Obviously I will keep what I think are the more original or important ones for myself, but there are several reasons why pursuing seemingly unoriginal ideas is still useful: 1) It gives you good practical experience. If you've never tried to find a good dataset that would answer your question, if you've never tried to analyze and summarize the data, and if you've never interpreted these findings in context for the target audience -- well, time to start. 2) Many supposedly established findings have the smell of academic urban legends because they are based on a single study that used an unimpressive sample size and didn't take into account some obvious confounding factors. Yet once it gets cited, it takes on a life of its own, as no one reads the original but simply "knows that study X showed Y." Replication studies are crucial to figure out if we were right. 3) Most published articles aren't terribly original anyway -- "here's yet another example of natural selection at work!" Still, the more astounding the mountain of evidence becomes, the more convinced we become that we are right. There are probably diminishing returns, though: we don't need yet another study showing that cognitive abilities all correlate with each other, but how pervasive is the influence of IQ -- do smart vs. dumb people prefer different types of art? 4) More mundane studies are easier to carry out, so you're not intimidated by the prospect of hunting down a solution to a Great Big Problem. (And if you liked chasing after Great Big Problems, you'd probably already be in academia or a private institute doing that, or preparing to do so in the near future.) 5) If the original study or idea was done awhile ago, improved technology may allow you to take a more in-depth look at it. For example, computers were pretty pathetic in the 1960s, and I'll be there are scores of dusty studies that would benefit from the power of modern home computers. 6) For mathematical models, the properties of a particular model may be so well known that you couldn't hope to contribute anything new on the abstract level. However, you could provide a novel interpretation of it by showing how it also models a phenomenon that no one has applied it to before. This is especially true for fields were the experts don't have much training in modeling, which tend to focus on human beings. Sociology is a perfect example -- here's a field that assumes the primary unit of society is the group, and that groups conflict and interact, while ignoring the individual differences within each group. This isn't a slight to the field, since there are group dynamics. Sociology cries out for differential equation models, where you ignore individuals and track classes of things, and typically only two or three classes! 7) For the studies that I will propose, the data would not be hard to collect, although the process from start to finish may be laborious (hey, that's life). So, I will not suggest studies that require fancy equipment, hundreds of unpaid volunteer subjects, and so on. If it is applying a well understood mathematical model to some new phenomenon, almost all of the work will already be done. However, I realize that we do have academic readers too, or readers who have graduate student friends in need of a study to publish, so occasionally I will propose something that would require access to many volunteers. Now, I don't have anything against editing Wikipedia or blogging per se, but let's get very real: most of it is a waste of time, which is why almost no academics do it. There are exceptional areas of Wikipedia, and there are exceptions in the blogosphere -- well, obviously we are, and so are bloggers like Steve Sailer, Audacious Epigone, Half Sigma, Inductivist, and others who obtain and analyze data to answer a question or hunch. If the blog is just a hobby, an afterthought after real work is being done in real life (as with my personal blog), that's OK too. What I want to see die is the practice of intellectual masturbation, where you only fool your brain into thinking that fruitful work is being done. "Participation" per se is no valid criterion for success -- I can participate in an act of masturbation, perhaps even while participating with others in a circle jerk, but I've only really accomplished something when I've contributed to increasing the fertility rate. Fortunately for everyone, though, the real world offers an abundance of problems begging to be fertilized by the seed of your brain -- get in there and tear that shit up. Labels: do it yourself studies |
  Razib's Home Page GNXP Archives Interviews Blogroll Principles of Population Genetics Genetics of Populations Molecular Evolution Quantitative Genetics Evolutionary Quantitative Genetics Evolutionary Genetics Evolution Molecular Markers, Natural History, and Evolution The Genetics of Human Populations Genetics and Analysis of Quantitative Traits Epistasis and Evolutionary Process Evolutionary Human Genetics Biometry Mathematical Models in Biology Speciation Evolutionary Genetics: Case Studies and Concepts Narrow Roads of Gene Land 1 Narrow Roads of Gene Land 2 Narrow Roads of Gene Land 3 Statistical Methods in Molecular Evolution The History and Geography of Human Genes Population Genetics and Microevolutionary Theory Population Genetics, Molecular Evolution, and the Neutral Theory Genetical Theory of Natural Selection Evolution and the Genetics of Populations Genetics and Origins of Species Tempo and Mode in Evolution Causes of Evolution Evolution The Great Human Diasporas Bones, Stones and Molecules Natural Selection and Social Theory Journey of Man Mapping Human History The Seven Daughters of Eve Evolution for Everyone Why Sex Matters Mother Nature Grooming, Gossip, and the Evolution of Language Genome R.A. Fisher, the Life of a Scientist Sewall Wright and Evolutionary Biology Origins of Theoretical Population Genetics A Reason for Everything The Ancestor's Tale Dragon Bone Hill Endless Forms Most Beautiful The Selfish Gene Adaptation and Natural Selection Nature via Nurture The Symbolic Species The Imitation Factor The Red Queen Out of Thin Air Mutants Evolutionary Dynamics The Origin of Species The Descent of Man Age of Abundance The Darwin Wars The Evolutionists The Creationists Of Moths and Men The Language Instinct How We Decide Predictably Irrational The Black Swan Fooled By Randomness Descartes' Baby Religion Explained In Gods We Trust Darwin's Cathedral A Theory of Religion The Meme Machine Synaptic Self The Mating Mind A Separate Creation The Number Sense The 10,000 Year Explosion The Math Gene Explaining Culture Origin and Evolution of Cultures Dawn of Human Culture The Origins of Virtue Prehistory of the Mind The Nurture Assumption The Moral Animal Born That Way No Two Alike Sociobiology Survival of the Prettiest The Blank Slate The g Factor The Origin Of The Mind Unto Others Defenders of the Truth The Cultural Origins of Human Cognition Before the Dawn Behavioral Genetics in the Postgenomic Era The Essential Difference Geography of Thought The Classical World The Fall of the Roman Empire The Fall of Rome History of Rome How Rome Fell The Making of a Christian Aristoracy The Rise of Western Christendom Keepers of the Keys of Heaven A History of the Byzantine State and Society Europe After Rome The Germanization of Early Medieval Christianity The Barbarian Conversion A History of Christianity God's War Infidels Fourth Crusade and the Sack of Constantinople The Sacred Chain Divided by the Faith Europe The Reformation Pursuit of Glory Albion's Seed 1848 Postwar From Plato to Nato China: A New History China in World History Genghis Khan and the Making of the Modern World Children of the Revolution When Baghdad Ruled the Muslim World The Great Arab Conquests After Tamerlane A History of Iran The Horse, the Wheel, and Language A World History Guns, Germs, and Steel The Human Web Plagues and Peoples 1491 A Concise Economic History of the World Power and Plenty A Splendid Exchange Contours of the World Economy 1-2030 AD Knowledge and the Wealth of Nations A Farewell to Alms The Ascent of Money The Great Divergence Clash of Extremes War and Peace and War Historical Dynamics The Age of Lincoln The Great Upheaval What Hath God Wrought Freedom Just Around the Corner Throes of Democracy Grand New Party A Beautiful Math When Genius Failed Catholicism and Freedom American Judaism
Archives
July 2005 August 2005 September 2005 October 2005 November 2005 December 2005 January 2006 February 2006 March 2006 April 2006 May 2006 June 2006 July 2006 August 2006 September 2006 October 2006 November 2006 December 2006 January 2007 February 2007 March 2007 April 2007 May 2007 June 2007 July 2007 August 2007 September 2007 October 2007 November 2007 December 2007 January 2008 February 2008 March 2008 April 2008 May 2008 June 2008 July 2008 August 2008 September 2008 October 2008 November 2008 December 2008 January 2009 February 2009 March 2009 April 2009 May 2009 June 2009 July 2009 August 2009 September 2009 October 2009 November 2009 December 2009 January 2010 February 2010 Hello Movable Type archives August 11,2002 August 18,2002 August 25,2002 September 01,2002 September 15,2002 October 20,2002 December 08,2002 December 22,2002 December 29,2002 January 05,2003 January 12,2003 January 19,2003 January 26,2003 February 02,2003 February 09,2003 February 16,2003 February 23,2003 March 02,2003 March 09,2003 March 16,2003 March 23,2003 March 30,2003 April 06,2003 April 13,2003 April 20,2003 April 27,2003 May 04,2003 May 11,2003 May 18,2003 May 25,2003 June 01,2003 June 08,2003 June 15,2003 June 22,2003 June 29,2003 July 06,2003 July 13,2003 July 20,2003 July 27,2003 August 03,2003 August 10,2003 August 17,2003 August 24,2003 August 31,2003 September 07,2003 September 14,2003 September 21,2003 September 28,2003 October 05,2003 October 12,2003 October 19,2003 October 26,2003 November 02,2003 November 09,2003 November 16,2003 November 23,2003 November 30,2003 December 07,2003 December 14,2003 December 21,2003 December 28,2003 January 04,2004 January 11,2004 January 18,2004 January 25,2004 February 01,2004 February 08,2004 February 15,2004 February 22,2004 February 29,2004 March 07,2004 March 14,2004 March 21,2004 March 28,2004 April 04,2004 April 11,2004 April 18,2004 April 25,2004 May 02,2004 May 09,2004 May 16,2004 May 23,2004 May 30,2004 June 06,2004 June 13,2004 June 20,2004 June 27,2004 July 04,2004 July 11,2004 July 18,2004 July 25,2004 August 01,2004 August 08,2004 August 15,2004 August 22,2004 August 29,2004 September 05,2004 September 12,2004 September 19,2004 September 26,2004 October 03,2004 October 10,2004 October 17,2004 October 24,2004 October 31,2004 November 07,2004 November 14,2004 November 21,2004 November 28,2004 December 05,2004 December 12,2004 December 19,2004 December 26,2004 January 02,2005 January 09,2005 January 16,2005 January 23,2005 January 30,2005 February 06,2005 February 13,2005 February 20,2005 February 27,2005 March 06,2005 March 13,2005 March 20,2005 March 27,2005 April 03,2005 April 10,2005 April 17,2005 April 24,2005 May 01,2005 May 08,2005 May 15,2005 May 22,2005 May 29,2005 June 05,2005 June 12,2005 June 19,2005 June 26,2005 July 03,2005 July 17,2005 August 07,2005 Blogspot archives June 2002 July 2002 August 2002 September 2002 October 2002 November 2002 December 2002
10 questions for....
Parag Khanna James Flynn Jon Entine Gregory Clark György Buzsáki Heather Mac Donald Bruce Lahn A.W.F. Edwards Luigi Luca Cavalli-Sforza Joseph LeDoux Matthew Stewart Charles Murray James F. Crow Adam K. Webb Justin L. Barrett David Haig Judith Rich Harris Ken Miller Dan Sperber Warren Treadgold Armand M. Leroi John Derbyshire
Blogs
The GiveWell Blog Your Religion Is False Colby Cosh Steve Hsu Audacious Epigone Catallaxy Files Inductivist 2 Blowhards Genetic Future Agnostic Steve Sailer Dienekes Derek Lowe Razib Khan Razib at Comment is Free Secular Right Glenn Reynolds Jim Miller Kevin McGrew John Hawks Peter Fost Randall Parker Less Wrong Charles Murray Carl Zimmer EconLog Marginal Revolution
Principles of Population Genetics
Genetics of Populations Molecular Evolution Quantitative Genetics Evolutionary Quantitative Genetics Evolutionary Genetics Evolution Molecular Markers, Natural History, and Evolution The Genetics of Human Populations Genetics and Analysis of Quantitative Traits Epistasis and Evolutionary Process Evolutionary Human Genetics Biometry Mathematical Models in Biology Speciation Evolutionary Genetics: Case Studies and Concepts Narrow Roads of Gene Land 1 Narrow Roads of Gene Land 2 Narrow Roads of Gene Land 3 Statistical Methods in Molecular Evolution The History and Geography of Human Genes Population Genetics and Microevolutionary Theory Population Genetics, Molecular Evolution, and the Neutral Theory Genetical Theory of Natural Selection Evolution and the Genetics of Populations Genetics and Origins of Species Tempo and Mode in Evolution Causes of Evolution Evolution The Great Human Diasporas Bones, Stones and Molecules Natural Selection and Social Theory Journey of Man Mapping Human History The Seven Daughters of Eve Evolution for Everyone Why Sex Matters Mother Nature Grooming, Gossip, and the Evolution of Language Genome R.A. Fisher, the Life of a Scientist Sewall Wright and Evolutionary Biology Origins of Theoretical Population Genetics A Reason for Everything The Ancestor's Tale Dragon Bone Hill Endless Forms Most Beautiful The Selfish Gene Adaptation and Natural Selection Nature via Nurture The Symbolic Species The Imitation Factor The Red Queen Out of Thin Air Mutants Evolutionary Dynamics The Origin of Species The Descent of Man Age of Abundance The Darwin Wars The Evolutionists The Creationists Of Moths and Men The Language Instinct How We Decide Predictably Irrational The Black Swan Fooled By Randomness Descartes' Baby Religion Explained In Gods We Trust Darwin's Cathedral A Theory of Religion The Meme Machine Synaptic Self The Mating Mind A Separate Creation The Number Sense The 10,000 Year Explosion The Math Gene Explaining Culture Origin and Evolution of Cultures Dawn of Human Culture The Origins of Virtue Prehistory of the Mind The Nurture Assumption The Moral Animal Born That Way No Two Alike Sociobiology Survival of the Prettiest The Blank Slate The g Factor The Origin Of The Mind Unto Others Defenders of the Truth The Cultural Origins of Human Cognition Before the Dawn Behavioral Genetics in the Postgenomic Era The Essential Difference Geography of Thought The Classical World The Fall of the Roman Empire The Fall of Rome History of Rome How Rome Fell The Making of a Christian Aristoracy The Rise of Western Christendom Keepers of the Keys of Heaven A History of the Byzantine State and Society Europe After Rome The Germanization of Early Medieval Christianity The Barbarian Conversion A History of Christianity God's War Infidels Fourth Crusade and the Sack of Constantinople The Sacred Chain Divided by the Faith Europe The Reformation Pursuit of Glory Albion's Seed 1848 Postwar From Plato to Nato China: A New History China in World History Genghis Khan and the Making of the Modern World Children of the Revolution When Baghdad Ruled the Muslim World The Great Arab Conquests After Tamerlane A History of Iran The Horse, the Wheel, and Language A World History Guns, Germs, and Steel The Human Web Plagues and Peoples 1491 A Concise Economic History of the World Power and Plenty A Splendid Exchange Contours of the World Economy 1-2030 AD Knowledge and the Wealth of Nations A Farewell to Alms The Ascent of Money The Great Divergence Clash of Extremes War and Peace and War Historical Dynamics The Age of Lincoln The Great Upheaval What Hath God Wrought Freedom Just Around the Corner Throes of Democracy Grand New Party A Beautiful Math When Genius Failed Catholicism and Freedom American Judaism   Policies Terms of use © http://www.gnxp.com Razib's total feed: |