|
Leave print-view
Sunday, April 29, 2007
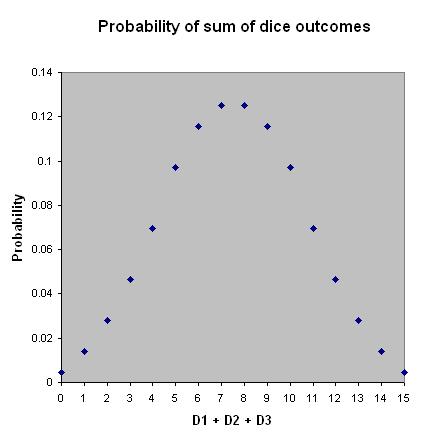
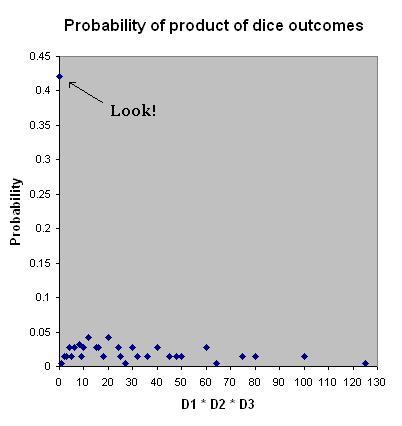
How often should we expect to observe events that are 40 standard deviations above the mean? Probably not ever. If we do observe such events more frequently than never, that may be because our initial guess was based on an incorrect model. To pick an example relevant to current events, how many people do you think you're capable of killing in cold blood -- that is, elaborately planning the set-up, commission, and aftermath? Let's assume you're a civilian, not a soldier. I'm guessing most people would say zero, with maybe 1-5% capable of killing in the low single digits, and they'd probably know the victims (e.g., jilted lover). Committing a spree shooting seems so out-there that we ought to observe such things only incredibly rarely (maybe once every 100 years?). Yet just recently a student at Virginia Tech killed 32, and not long ago the Columbine High School shooters killed 12, and in 1966 the UT-Austin shooter killed 13 (not to mention the dozens of wounded per incident). Such shootings are of course rare, but there's "rare" and then there's rare. This means that we're probably looking at the problem the wrong way: it's likely not true that number of people you could kill is normally distributed about a very low mean (say less than 1). What could make such extreme events so common? The math here will bore those who have studied probability, but hopefully the examples will be worth reading about. And for those who haven't studied probability, this will make a nice "math for the people" intro to different types of distributions. One easy way for extreme events to be more common than seems plausible is if several variables are involved which interact multiplicatively with each other. To understand some key differences between an additive vs. multiplicative scenario, consider rolling three 6-sided dice, each numbered 0 - 5, with each face equally likely and each die independent of the others. Suppose in Game A we record the "score" as the sum of the numbers showing, while in Game B we record their product.* The probability distributions of scores in the two Games are shown in the pictures linked to below:


We immediately see that the range of possible scores in A is far narrower than in B: 0 - 15 vs. 0 - 125, respectively. Thus, the "extreme score" is much more extreme in the multiplicative case. Importantly, the highest score in A is as likely to happen as its counterpart in B, since there is only 1 outcome out of 216 that will result in a highest score for either Game (all 5s). However, the lowest score in A is less likely to happen than its counterpart in B, since only 1 of 216 outcomes will give it in A (all 0s), but in Game B there are (1 - (5/6)^3) or about 42% of the 216 outcomes -- so, 91 outcomes (in B, just one 0 is needed for the entire score to be 0). We can thus tell that the probability distribution is symmetrical in A (like a bell curve), but highly skewed in B -- in the latter, most of the mass of the curve is concentrated at the lower values (the median is ~5). Still, the expected value is higher in B than in A (15.6 vs 7.5), due to the greater extreme values skewing the distribution in B.
To see how far off-base our thinking can go if we misjudge the way that the variables are related to the score, let's say we observed the equivalent of a score of 125. Had we assumed that the variables were contributing to the score additively, we would then say that this data-point was (125 - 7.5) / 2.96 = 40 SD above the mean! For comparison, this would be like measuring the height of a human being who was 16 feet tall. That's so rare you'd think it was a typo. However, if we paused and thought "y'know, maybe the variables interact with each other," then we might settle on the more realistic idea that such an event had a probability of 1/216 = .005. Converting this into a z-score gives 2.6 SD above the mean, which is still rare in a sense but far more modest and realistic than the erroneous estimate.
Returning to reality, in summarizing the findings of much of the creativity research, I noted that creativity or genius appears to result from the multiplicative interaction between, for instance, high intelligence, together with various personality traits like Psychoticism. This creates a skewed, log-normal distribution whereby most people don't produce anything creative enough to earn the esteem of those who matter, and a tiny handful dominate entire fields. That's why the dice range from 0 to 5 instead of from 1 to 6 in the example above: 0 is special since it indicates lack of some key trait (intelligence, curiosity, persistence, etc.).
It's conceivable that "cold-blooded homicidal output" is also log-normally distributed, with most people not killing anyone in cold blood (or at all), and a tiny few killing lots (e.g., spree shooters, serial killers, etc.). We know from the work on the MAO gene that those with "warrior genes" typically commit violence only when they treated violently during childhood, so that's at least one interaction effect, as well as the sex-by-genotype interaction; presumably there are others (perhaps being taunted frequently at school). Also, researchers in finance talk about how frequently disasterous events occur.
And on the less gruesome side, personal "allure" is probably log-normally distributed, not just because physical attractiveness is probably so distributed, but a person's demeanor animates (interacts with) their plastic form. To make this intuitively clear, model your attraction to someone according to the metaphor "to have a crush" -- consider the average person who embodies your preferences for physical attractiveness (who has traits P), and for intelligence & personality (who has traits I). Let's say that those with traits P make you weak enough to feel like you were burdened by a 10-pound weight, and that those with traits I also made you feel burdened by a 10-pound weight. Now, how much of a sinking feeling would you get if the person had it all in one package? I'd guess that you'd feel weighed down by 100 pounds, not just 20. Ah, romantic love -- one local sickness compounded by many others!
In this way, "freak" occurrences may not be so freaky after all, if the proper relationship holds between the factors that contribute to the event.
* This is not exactly the difference between normal and log-normal distibutions, since each random variable (the outcome of a particular die) isn't normally distributed but uniformly distributed. However, rather than concoct some bizarre game where the outcomes for a die are normal, I've altered some irrelevant details to convey the gist of the difference while keeping the analogy easily accessible.
|