The article Razib
mentioned earlier on the correlation between genetics and language type has
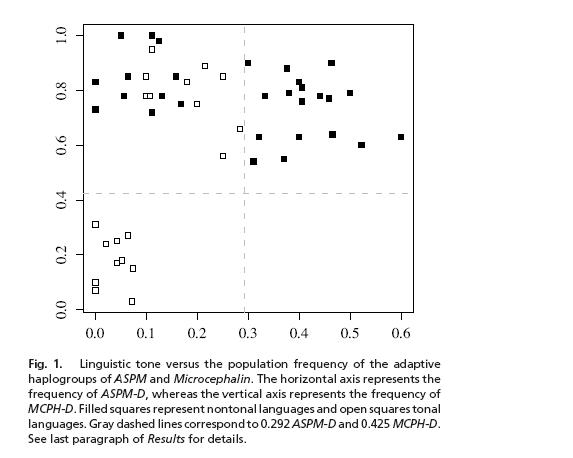
been published. Effectively, the results of the paper are in their one figure (right), which shows population frequency of the two alleles on the x and y axes. The filled squares represent non-tonal languages, and the empty squares tonal languages. There's an association between allele frequencies and language type, and the magnitude of the association is an oulier when considering other loci in the genome, suggesting that it is not simply due to population migration and history. My comments:
1. I have never seen an article so apologetic about its conclusions. About every other sentence explains what they have not shown-- a gene for "speaking Chinese", a proof of causality of the alleles, any sort of racial anything. Probably the result of unsympathetic reviewers.
2. The approach they take is one that's likely to be widely employed as more world-wide genotype data become available-- make a hypothesis that there should be a correlation between allele x and world-wide variable y, then test the correlation for a number of loci. If your allele x is an outlier, you've found something interesting. I'm not sure of the best way to analyse this data, nor am I sure the outlier approach is really effective. Some sort of statistical framework would be nice here, as a way of truly assessing the significance of a result like this.
3. As both ASPM and MCPH are polymorphic within populations, the best way to test the authors' hypothesis (as I'm sure they're well aware) is to do an association study on any of the variables they mention as being involved in slight biases towards a given language type. This would be interesting. But the authors also claim that the lingistic bias towards a language type is small, but amplified by cultural transmission, so possibly undetectable on an individual level. So can this hypothesis be falsified?
4. I'm trying to figure out the logic behind the placement of the dotted lines in the figure. It's not halfway between to min and max allele frequencies. It's not computed in any manner. Yet they make claims about the relative frequencies of each type of language in each quadrant. This seems highly questionable-- the human mind is highly capable of detecting patterns and forming groups, even when data are random. I'm not claiming the data points here are random, simply that the positioning of the lines in the figure serves to bias our thinking (note that a slight move to the right of the vertical line, or a move up to 50% on the horizontal line, would put a population in a quadrant they don't think it should belong in).
Overall, the paper is suggestive. Maybe highly suggestive? But I'd wait for a bit more data before coming to any conclusions.
UPDATE: Mark Lieberman at Language Log posts on the study, explaining more concretely
the difficulties of the outlier approach. Bob Ladd, one of the authors of the study, then responds in
a guest post:
Consequently, we've gone about as far as we can go with statistics; the only real confirmation that we are onto something will now come from experimental work demonstrating the existence of the hypothesized genetically-induced "cognitive bias" in individuals, followed by studies clarifying the neurological basis of the bias. As Daniel Nettle says in his Commentary on the print version of our paper (appearing soon), our work is really hypothesis-generating rather than hypothesis-testing.
We are now generating precise hypotheses about the nature of the bias, and hope to start testing them soon.
...
Now, it's certainly true, as Mark says, that our geographical correlations would mean more if they had proceeded from some experimental demonstration of some sort of genetically linked, language-related, cognitive/behavioral/perceptual difference. But given the widespread assumption (rooted in the Boasian tradition, but with a significant contemporary boost from Chomsky) that the human language faculty is absolutely uniform across the species, it's very unlikely that we would have been able to get funding to look for such a difference first. So we started by doing something we could do on our own without such support, namely testing the apparent correlation. Having done that, we hope we are now in a better position to apply for funding for the expensive part of the research
Labels: Cognitive Science, Genetics