
|
Wednesday, August 19, 2009
The greater fool theory 1: A mostly verbal mathematical model
posted by
agnostic @ 8/19/2009 09:22:00 PM
Here is a brief description of the idea that price bubbles are caused by people buying something, not necessarily because they think it's worth anything, but because they think they can find an even greater fool to buy it at a higher price. This continues until no more such fools can be found, and this bust drives prices back down to what they were before the boom began.
I didn't see any references to mathematical models of the theory at Wikipedia or through Googling around a bit, so I made one up today at Starbucks since I didn't have anything to read to pass the time. Because I'm not an economist, I don't know how original it is, or how it compares with alternative models of the greater fool theory (if they exist). So, this is intended just as an exercise in modeling, explaining the model, and hopefully shedding some light on how the world works. I've kept most of the exposition straightforward and largely verbal, so that you don't need to know much math at all to understand what the model says and what its implications are. In part 1, I lay out the logic of the model and explain enough of it to show that it is capable of producing a single round of boom-and-bust for price hype. Part 2 will provide more mathematical detail about how the dynamics unfold, a phase plane analysis, and graphs of how the variables of interest would change over time, to better wrap your brain around what the model predicts. This is a dynamic model, or one that tracks how things change over time -- after all, we want to see how price, the number of fools, etc., evolves. It is made of several differential equations, and all these equations say is what causes something of interest to go up or go down over time. (You may recall that the sign of a derivative tells you whether a function is increasing or decreasing, and the magnitude says by how much.) I'll only explain what is absolutely necessary for the reader to see what's going on, with the less necessary math being confined to footnotes. First, we set up the basic picture before we write down equations. My version of the greater fool theory goes like this. There is a population of people, and during a price bubble they can fall into three mutually exclusive groups: suckers (S), who are susceptible to joining in on the bubble; investors (I), who currently own the speculative stuff (such as a home bought for speculation); and those who are retired from the bubble (R), who used to be investors but have gotten rid of their investment. And of course there is the price of the thing -- I model only the extra price that it enjoys due to hype (P), above its fundamental value, since this is the only component of price that changes radically during the bubble. I set the population to be fixed in size during the bubble, since growth or decline is negligible over the handful of years that the bubble lasts. I also set the amount of speculative stuff to be fixed, which is less general -- supply should shoot up to meet the rising demand during a bubble. So, this model is restricted to cases where you can't produce lots more of the stuff, relative to how much already exists, on the time-scale of the bubble's boom stage (say, 5 years or less). Or perhaps no more of it will be produced at all, such as video game consoles from decades ago that the original manufacturers will never bring back into production, but which nostalgic fans have taken to buying and selling speculatively (like NEC's TurboDuo). Last, the amount of stuff that each investor has is the same across all investors and stays constant -- say, if each investor always owned just one speculative home. At the start of the bubble, there is a certain number of early investors. In order to sell their stuff, they need to meet a sucker to sell it to. When they meet -- and I assume the two groups are moving around independently of each other -- there is a probability that the sale will be made. If they make a deal, the sucker is now an investor, and the former investor is now retired. In this model, retireds do not again become suckers -- they consider themselves lucky to have found a greater fool and stay out of the bubble for good afterward. That's the extent of how people change between groups. As for price hype, again I'm not an economist, so the exact formula may differ from what's standard. I take it to respond positively to demand -- namely, the number of suckers -- and that there is a multiplier that serves as a reality check. This reality check should be weak at the start when most non-investors are suckers, and should be strong near the end when most non-investors are retired. In other words, the price hype at the beginning is a near total distortion -- nearly 0% accurate -- whereas the price hype near the end is nearly 100% accurate. This will make more sense once we write down formulas. Now we get to the differential equations for how these things change. We write down one equation for each variable whose values we're tracking over time. I use apostrophes to denote the derivative with respect to time (i.e., rate of change): S' = -aSI Since suckers can only lose members (by turning into investors), there is only one term, and it shows how suckers decline (negative sign). Remember, retireds do not go back into the pool of potential buyers. And investors either make a sale and go into the retired group, or they sit on their stuff in hope of selling, so they never contribute to the growth of suckers. Thus, there is no growth term. The parameter a shows the probability that, when a sucker and an investor meet, the investor will transfer his stuff to the sucker. ("Parameter" is another word for "constant," in contrast to a variable that changes.) The reason we use the product of S and I is that this is essentially the rate at which the two groups encounter each other when they move around independently of each other. [1] I' = aSI - aSI = 0 Investors both grow and decline, so one term is positive and the other negative. They grow by having a sucker join their ranks, which as we saw above happens at rate aSI. However, each time that happens, the investor loses his stuff and becomes retired. That happens at the same rate, and the negative sign just shows that this causes I to decline. When we simplify, we get I' = 0 -- that is, the number of investors does not change over time. That makes sense because each bundle of stuff always has an owner, regardless of how it may change hands, somewhat like the game of hot potato. When something doesn't change, it is constant, so whenever we see I from now on, we'll know that this is just another parameter, not a variable that changes. In particular, it refers to the initial number of early investors who get the bubble going. R' = aSI Retireds never join the suckers again. And recall the mindset of a retired person -- they knew the stuff was junk and are glad to have gotten through the selling process, so they cannot be sold the stuff again to become investors once more. Thus, there is no way for them to lose numbers. They grow by former investors making a sale and becoming retired, which once again happens at rate aSI. Here's the neat thing: notice that S' + R' = -aSI + aSI = 0. The sum of the two derivatives equals zero, and since taking a derivative shows the distributive property, this also means that (S + R)' = 0. That is, the sum of suckers and retireds does not change over time. This makes sense since, if the number of investors stays constant, the leftovers -- suckers and retireds -- is constant, regardless of how each separate group grows or shrinks. We can take this further to note that S' + I' + R' = 0, which means (S + I + R)' = 0. That is, the combined size of all three groups does not change over time -- which is just what we claimed by keeping total population size constant. (Otherwise, each group would have birth and death terms, aside from the terms that show how their members switch between groups.) We'll call this constant total population size N. So, S + I + R = N. Now, I is just a constant, so we'll move it to the other side: S + R = N - I. We have two variables, S and R, but we just wrote an equation connecting them, so we can re-write one in terms of the other. I'll choose R, but it doesn't matter. So, R = N - I - S, and anywhere we see R, we can replace it with N - I - S. In other words, we've removed R from our focus -- we can always get it from knowing what the variable S is, as well as the two parameters N and I. That means the equation for R' only gives us redundant information, and we can ignore it. We can also ignore the I' equation, since it just tells us that I is constant, and we're only interested in things that change. So we're left with just the S' equation. Now we move on to the price hype formula and how it changes over time. First, the formula for price as a function of demand and the reality check, since hype is never totally irrational and at least tries to take stock of reality: P = bS(R / Rmax) = bS(R / (N - I)) Demand is driven by the number of suckers -- the ones who eventually want to get in on the bubble -- and the parameter b says how strongly demand responds to the number of suckers. The multiplier (R / Rmax) provides a reality check. If you landed from Mars and only knew the number of suckers, you would also want to know how many retireds there were -- if there were few retireds, that would tell you the bubble had only just begun, so that hype is likely to be high and to go even higher short-term. Thus, this filter should not let much of the demand information through. Indeed, when R is very low compared to Rmax, the multiplier is near 0. However, if you saw that there were many retireds, that would say the bubble was near its bust moment, and that the information from demand is very accurate by this point. Indeed, when R is near Rmax, the multiplier is near 1 and the filter lets just about all of the demand information through. What is Rmax? It is the value when no one is a sucker and everyone is retired, aside from the constant number of investors. Looking above at the equation S + R = N - I, we see that when there are no suckers, R = N - I. Now we need to find the differential equation for how P changes over time. Using the product rule for derivatives [2], we get: P' = (abI / (N - I)) * S(2S + I - N) Since a, b, I, and N - I are always positive, and since S is positive except for the very end of the bubble when it is 0, in the meantime, whether price hype shoots up or crashes down depends on whether the term 2S + I - N is positive or negative. It is positive and price hype grows when S exceeds (N - I) / 2, which is half the size of non-investors. It is negative and price hype declines when S is below (N - I) / 2. It is 0 and price hype momentarily stalls out when S is exactly (N - I) / 2. Because the bubble starts with all non-investors being suckers, S is initially N - I, which is greater than (N - I) / 2. So at first the price hype shoots up. However, remember that S only declines -- as more and more of the suckers are drawn into the bubble (some of whom may also make sales and become retireds), S will inevitably fall below (N - I) / 2 and price hype will start to contract. When S inevitably reaches 0 -- when all non-investors are out of the bubble for good -- then P = 0 (recall that P = bS(R / Rmax)). Moreover, at that time P' = 0 too. Thus, at the end, price hype has completely evaporated and it will stay that way. This is a single round of boom-and-bust for price hype. In this post, I've shown how some pretty simple "greater fool" dynamics can lead to a boom-and-bust pattern for price hype. You can quibble with all of the assumptions I've made, but the model shows that the greater fools theory is a viable explanation for price bubbles. I've relaxed some of the assumptions to see if it makes a difference, like making the decline of S be a saturating rather than linear function of S, and so far they don't seem to affect things qualitatively. A more realistic model would have P appear in the equation for S' -- that is, to have price hype affect the probability of making a sale. Or rather, the trend of prices (P' ) should affect sale probability -- if suckers see that price hype is increasing, they should want to get in on the bubble, and to stay put if price hype is dropping. Also, allowing retireds to re-enter the pool of suckers would be more general and would almost certainly lead to sustained cycles of boom-and-bust, rather than a single round. But that's for another slow afternoon. In part 2, I'll go into more mathematical detail about how we see what states this system is at rest in, and whether they are stable to disruptions or not. I'll look more at the formula for the maximum level of price hype, and interpret that in real-world terms in order to see what things will give us larger-amplitude bubbles. I'll provide a picture of the phase plane, which shows what the equilibrium points are, and how the variables will change in value on their way from their starting values to the final ones. I'll also have a couple of graphs showing how the number of suckers and retireds, and the amount of price hype, change over time. [1] Draw one person at random, and the chance that they're a sucker reflects S. Draw another one at random, and the chance that they're an investor reflects I, since the draws are independent. The chance of doing both is just the product of the two separate probabilities. [2] P' = (bS(R / Rmax))' = (b / (Rmax)) (S' * R + S * R') A little algebra, which you can confirm by hand or using Maple, gives the equation in the main body for P'. Labels: Behavioral Economics, Economics, mathematics, Modeling
Tuesday, September 02, 2008
As a special case of the downward trend in homicide and forcible rape beginning in the early 1990s, from 1990 to 2004, sexual abuse of minors steadily declined by 49%, reversing an upward trend from the 15 years before 1990; and from 1993 to 2004, sexual assaults against 12 to 17 year-olds steadily declined by 67%. See Finkelhor & Jones (2006) (free PDF here) for a review of the data, why they are real declines, and some proposed explanations. Also see Wolak et al. (2008) (free PDF here) for a review of the fact and fiction about internet sexual predators -- in particular, it appears that most sexual relationships involving teenage females that began with internet contact are voluntary (although still statutory rape if the female is under the age of consent), often repeated, and that the males rarely use deception. Unwholesome, but not what you see on To Catch a Predator.
Not to put too fine a point on it, but the recent panic that the mass media have been fueling about "sexual predators" is horseshit. For the same methodological reasons as in this post on the rape hysterias, I look at data on the popularity of the "sexual predator" theme in the New York Times. It is the opposite of the prediction from a "following the beat" view of journalistic practice, instead fitting a "spreading an unfounded rumor" view. I propose a simple model and estimate the annual growth rate of the rumor. First, let's see how many articles were written in the NYT in a given year that contained "sexual predator," "sex predator," or the plural forms of these two terms. Here is a graph: 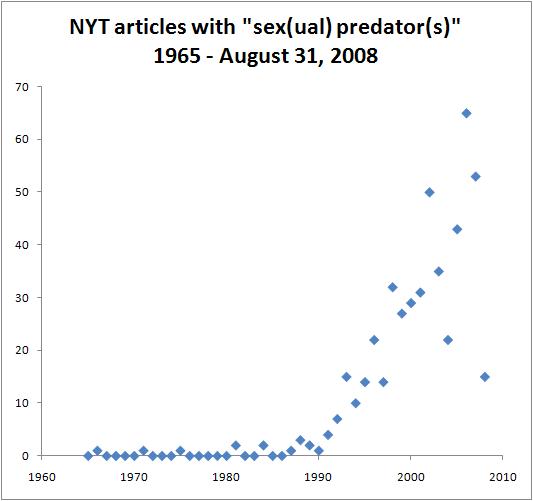 Right away we observe that the coverage is completely outta whack with the crime statistics on the ground: the phrases first appear in 1966, but there is essentially no coverage up through 1980, a moderate increase until 1990, and an explosion of articles starting around 1990. Because the increase in coverage cannot be explained by a rational response to easily discovered crime statistics, we conclude that it is an irrational "moral panic" -- if the sexual predator did not exist, it would be necessary to invent him. Going further, let's look at the data from 1981 to 2007. I start with 1981 because that is the first year when at least 2 articles appear -- 1 article every 5 or 10 years you could write off as flukes -- and I drop 2008 since the year is not done yet:  Of the typical curves used to fit data, here the exponential does the best: r^2 = 0.8772, and there is a theoretical reason to expect exponential growth. Actually, a quadratic curve improves r^2 by 0.0037, but that's not very much, and it doesn't illuminate what's going on. By setting 1981 equal to t = 1, and calling the number of articles N, the curve above is: N(t) = 0.8896*exp(0.1665*t) - 1 So, the estimated annual growth rate is 0.1665. An exponential function solves a differential equation of the form: dN/dt = r*N In words, the rate of increase in the number of articles is directly proportional to the current number of articles, where r is the growth rate we just estimated above. This says that somehow each article begets more articles which beget more articles. This is how a rumor spreads, although "articles written" are technically not the same thing as "people who have heard the rumor." Perhaps in the future the number of articles will saturate at some level, and we will have to re-model it using logistic growth. Or the meme could become unfashionable and the number will plummet to 0, in which case we'd use a boom-and-bust model. These two more realistic models are variations on the S-I-R model of the spread of contagious diseases, the only difference being whether the "infected" people can lose their infectivity or stay infected forever. Clearly the unlimited exponential growth model is inadequate because the total number of articles in all of the NYT is bounded, so the articles written on "sexual predators" cannot increase without bound. But since their number has not saturated yet (logistic model) or crashed downward (boom-and-bust model), we can't decide between the two more plausible models, let alone estimate the related parameters (like the steady-state number of articles in the logistic model). What is important here is that we have shown that the popularity of the "sexual predator" idea behaves like a rumor and takes on a life of its own or fuels its own growth. To wrap up, the panic over "sexual predators" is a lot like the Early Modern witch-hunts, which could not have succeeded without mass communication to spread the rumors of well-to-do worry-warts. Because it's easier to swallow rumors than to investigate them, there's a clear incentive for most reporters to do just that. And most of the blogosphere too, for that matter. The desire to know is just not uniformly distributed among the population, even among the affluent sectors. That's something to consider any time you find yourself parroting the hype -- if it were based on good work, then it would pay to buy into it. But most journalists are too stupid, lazy, credulous, or moralistic to figure out what's going on. And most of the blogosphere too, for that matter. Labels: crime, culture, mathematics
Sunday, September 30, 2007
"Good mathematicians see analogies. Great mathematicians see analogies between analogies."
--Stefan Banach A recent Cognitive Daily post called "Why aren't more women in science" (part 1) reviews some of the lit on sex differences in cognitive abilities. Dave Munger notes: In the verbal portion of the [SAT] test, the male advantage is eliminated if the analogy portion of the test is eliminated; arguably this is more a test of mapping relationships than literacy. The analogy portion was, of course, scrapped as of the spring 2005 SAT. [1] The boldfaced clause above shows why it matters more than the other Verbal portions: figuring out relationships between ideas matters, and reporting what some author said does not. Analogies are highly g-loaded, reading comprehension much less so. But aside from better detecting who the smarties are, analogies are more reflective of real-world math, science, and engineering. (And they matter in the humanities too [2].) If A got one more math question than B, but B got three more analogy questions than A, I'd bet on B doing better in math, even if an IQ test showed they had the same IQ. What follows is mostly a diversion to show the importance of analogies in math, starting with high school material and moving to some college material. I hope you learn something new, but mostly the goal is to put it on the record, with examples, how important a person's verbal analogy score is in predicting their success in math and science. Example 1. A bouncy-ball is dropped from 2 feet, and after hitting the ground, bounces up only 1/2 as high as its previous maximum height. Pretend that it bounces forever like this. In the long run, how much distance does the ball travel? We can make a table that shows how much distance the ball travels in a particular trip, either up or down, like so: Trip 1, 2, 3, 4, 5, 6, 7, ... Dist. 2, 1, 1, 1/2, 1/2, 1/4, 1/4, ... This problem is introduced in a pre-calculus class during the unit on the sum of an infinite geometric series -- infinite because it starts but never ends, and "geometric" meaning you multiply by the same number to get from one term to the next. The formula for such a sum is t1 / (1 - r), where t1 is the first term, and r is the constant that multiplies one term to get to the next. So if we only had these values, we'd be all set! Unfortunately, if we guess that r is 1/2, when we try to go from 1 to 1 -- we don't multiply by 1/2 anymore (or from 1/2 to 1/2). Damn. Plainly, the above series is not geometric, and at that point most students will opt to make better use of their time by yakking with friends on their cell phone. Ah, but the students in the class who are good analogical thinkers will notice a geometric series hiding behind the series above -- in fact, they'll discover two of them. The terms of one are interlocking with the terms of the other, like two rows of teeth that complete a zipper. That analogy suggests a strategy: unzip the above series. Then we have two series that go: 2, 1, 1/2, 1/4, ... and 1, 1/2, 1/4, ... Bingo! In each of these, you multiply by a constant (1/2) to get from one term to the next. And we know the first term of each, so we can plug in values for t1 and r in the sum formula. We get 2 / (1 - 1/2) = 4, and 1 / (1 - 1/2) = 2. So all together, the ball traveled 6 feet. That's a neat analogy, but it only makes sense when there are two series meshed into one. We'd like to generalize to any number of series that dovetail into one -- and no one makes zippers with more than two rows of teeth. So a better analogy might be the following:  Here there are two strands woven one around the other infinitely, with beads bearing numbers that face us, and there is a knot at the start where the strands fuse. Could we think up series with three or more geometric series hiding inside them? Sure, just as we could make a rope with three or more strands. And to make that series easy to solve, we would just unbraid the strands and work with the beads of each one separately. See note [3] for more uses of this braid analogy. Example 2. Here are some (x,y) pairs associated with a function. What is the degree of this function? That is, does it look like x, x^2, x^3, etc.? x = 1, 2, 3, 4, 5, 6... y = 2, 14, 34, 62, 98, 142... This problem also comes from high school math -- or middle school, if you took algebra then. There, you were taught to look for the difference between consecutive terms, and maybe repeat this process, until you got a sequence of the same number. The number of runs you have to make is the degree of the function. So for the above, the differences are: 12, 20, 28, 36, 44 OK, not the same number, but take the difference again: 8, 8, 8, 8 Ta-da. We had to go through 2 runs, so it must be some function like x^2 (in fact, it is 4x^2 - 2). I guarantee you never knew why this worked when you learned it -- and even after calculus or more advanced math, you may still have treated it as a mysterious trick. But there are analogies between discrete and continuous areas of math, and they are pervasive. If you took at least a semester of calculus, you know that if you take the 1st derivative of a function like 4x^2 - 2, you get something with the independent variable still in it -- 8x. And sure enough, in our discrete case, the first differences are 8x plus a constant 4. But if you then take the derivative of the derivative, you get a constant -- 8, the same 8 that appeared in our constant sequence after the 2nd run. A constant second difference in the discrete case is analogous to a constant second derivative in the continuous case. That also shows why you knew, back in high school, that you didn't have a polynomial function like x or x^2 or x^3 when you saw something like this: x = 1, 2, 3, 4, 5, 6... y = 2, 4, 8, 16, 32, 64... You can take differences of differences of differences of... and you'll never get a constnant sequence for this function, which is 2^x. In first-semester calculus, you learned that e^x is its own derivative, so that if you keep taking the derivative over and over, you always get back e^x -- the independent variable never goes away, so you never get a constant. This resilience to your effort to tease a constant derivative out of it is true of all exponential functions, which by analogy tells us that we'd never come up with a constant difference in the discrete case above. Since there are a billion other discrete-continuous analogies, I'll leave it there. I don't think they're that neat since it's only like switching between a British and American accent, not like translating between Farsi and Chinese. On a closing note, the entire domain of represenation theory in algebra is based on finding good analogies: they attempt to better understand how some group works by casting the problem in terms of matrices and linear algebra, which are better understood. All of this shows how indispensable this way of thinking is to fields that many assume are primarily about visuospatial skills (though those are key too). Analogies are to all types of thinkers what SONAR and nets are to deep-sea fishermen regardless of which species they hunt. [1] According to CollegeBoard's 2007 national report of college-bound seniors, it does appear that within the past couple of years, the male mean for Verbal is only about two points above the female mean, shrinking from a difference of about 11 to 12 points that had persisted since about 1980. And at the high end, in 2007, 1.98 % of males and 1.84 % of females scored 750 - 800. Data from other years on the elite scorers are not contained in the 2007 report, and I'm not interested enough in this topic to pursue them. The point is that gutting the analogy portion seems to have served its purpose. [2] When the retiring of the analogy questions was announced, an educator named Ted Sutton got an op-ed into the very liberal Boston Globe and made a guest appearance on the very liberal radio show On Point (which airs on NPR). He lamented the change, focusing on the centrality of analogies to the great philosophical and humanistic traditions. Older-style liberals like Sutton appear unaware that their social engineering cousins are the ones responsible for flushing great ideas down the drain, so that the gap between the sexes on a test might close. At least there are still analogies on the GRE -- despite a plan to re-vamp the test with the same gap-narrowing agenda in mind. And thank God for the Miller Analogies Test -- not a single "how does the author most likely feel about X" question at all! [3] The braid idea can also guide your intuition when you have a homework problem in a college-level course that says: "Prove that a countable union of countable sets is countable." I provided a visual proof here (with a more detailed proof at the end), but I didn't think of the braid analogy, which makes it even easier to picture. The argument is as I wrote before, but when you're introducing yet another countable set into the union, it's like adding a new strand to a rope. You look at the place where the n strands have shown themselves once -- and before the first strand winds around the second time, you push it over and braid in your new strand. When they n strands have shown up twice, you push the first strand over before it winds around the third time, and there's the second place where the new strand goes. And so on to infinity. The union of these strands is a rope whose beads are countable and, more importantly, ordered in a straightforward way. More explicitly, we can think of the strands as equivalence classes and the rope as the space they fill out. We can imagine a rope that extends infinitely in either direction, like the even and odd integers woven together. We've already seen a rope with a knot but which continues to weave itself forever in one direction. A rope with knots at both ends is pretty boring -- unless they were the same point, i.e. the rope circled back so that each strand fed back into itself, as with a sequence that's cyclic (for instance: x, y, x^2, y^2, x^3, y^3, x, y, ...). Labels: general intelligence, mathematics
Wednesday, August 08, 2007
Brains and beauty: review of Math Doesn't Suck by McKellar
posted by
agnostic @ 8/08/2007 12:03:00 PM
Barbie was right: math is hard. Most people find this out in middle school when algebra is introduced, and even the smarties become humbled in college. Danica McKellar, who some readers will remember as Winnie Cooper from The Wonder Years, recently published a book that's part math textbook, part motivational speech, and part "modern girl's guide to life" -- Math Doesn't Suck: How to Survive Middle-School Math Without Losing Your Mind or Breaking a Nail. Tara Smith, who runs the blog Aetiology, recently interviewed McKellar, and has hosted several general discussions about the book here and here. (Another favorable review from The Intersection.) I want to review Math Doesn't Suck in the context of these discussions, especially the one on whether math books that appeal to girls' interest in fashion are apt to turn them into "consumerist tools of the patriarchy". (The intersection of radical feminist ideology and activist pedagogy: where outside parody would be superfluous.)
I had to kill several hours after work tonight before going home, so I perused Math Doesn't Suck at Barnes & Noble, reading carefully just the parts that set it apart from other textbooks (I'm proud to say I already knew the middle school math). First, let me say that I'm not qualified to review its pedagogical strengths -- that's best left to controlled experiments with large sample sizes, an idea that's seldom raised whenever a new educational miracle arrives. Instead I'll focus first on the lessons to be learned, and then review the book's tone, use of examples, and appropriateness for various groups. I. Lessons learned The key lesson to take away from this book is that we are witnessing the twilight of the days when "women in science" activists browbeat girly girls into behaving more like Amazons in some imaginary war of the sexes within the academy. Let's look at those two ideas. First, McKellar takes an unabashedly anti-Amazon approach, some aspects of which I'll discuss in the review. Briefly though, she emphasizes the following qualities throughout: humility, gracefulness, zeal or diligence, snuffing out envy, maintaining a pleasant appearance, and self-reliance but also seeking help when needed. Second, and more importantly, McKellar bases her book on the assumption that girls are their own worst enemies, not that the patriarchal oppressors conspire to keep them down. I know, you must be falling out of your chair laughing when someone suggests that the physically unprepossessing and emotionally retarded nerds who tend to run university math departments are the incarnation of masculinity and power, but anything goes in rad-fem ideology. McKellar instead sees individual girls acting counter to their own best interests -- that's true of both sexes, since we're riddled to the core with flaws, not being blank slates or angels -- as well as being the targets of their same-sex competitors. It is telling that the only two anecdotes in which a girl is made to feel awful about her math skills involve female adversaries. One woman tells the story of another girl making fun of her as a nerd for scoring highly on a math test. And McKellar herself relates an instance when her science teacher pulled her aside to ask how she'd managed to score so highly, given how pretty and stylish she was. No, this wasn't a male chauvinist from the 1950s but rather a female girl-hater from the late 1980s. Rather than shaming her into downplaying her girliness, this incident emboldened McKellar to stick it to The Woman -- she didn't have to "dress like a dork" just to be good at math. (And guys, lest you think you're going to get off easily, I have a post in the works on improving your personal appearance, as befits a mature and responsible professional.) That the true sources of present-day female underachievement have little to do with patriarchal oppression could only be a surprise to someone who just landed here from Mars. Last year there was a WSJ article on how women in the workplace tend not to treat each other well, to such an extent that a majority feel their male bosses treat them better than do their female bosses! And as far as popular fiction goes, the three greatest teen movies of the past 20 years all share the theme of female-female sabotage, and none of it due to the machinations of male manipulators: Heathers, Clueless, and Mean Girls. Incidentally, why on Earth does Hollywood choose actresses like Denise Richards and Lindsay Lohan to play nuclear physicists and mathletes, given how dopey they are? McKellar, just to pick the most convenient example, would have made a much more convincing protagonist of Mean Girls, and is a superior role model to Lohan. OK, so that's true of anyone who isn't incarcerated or walking the streets, but you know what I meant. II. Review Tone. McKellar uses a very informal and conversational tone throughout, which aside from making the exposition clearer to beginning students, also has a disarming effect, since suspicious readers will probably expect a stern, lecturing tone since the book is about practicing math. One thing I learned if I need to write a popular book for teenage girls: ask lots of personal questions to the reader and use exclamation points frequently. And mention boys in every other sentence. Moreover, the tone is always one of encouragement, like that of a cheerleader getting the student body fired up during a pep ralley. There is no condescension toward their concerns and no trace of male-bashing. And what McKellar is encouraging them to do is not to try to one-up the boys -- like, "go show those boys you can take them on in math!" -- since that "something to prove" mindset will only exacerbate their existing insecurities. Rather, she appeals to their desire for personal accomplishment. Individuals differ in their levels of achievement striving, so this appeal will not resonate with all readers, but it is worth noting that, even though there are pronounced sex differences in the means of almost all personality traits, the facet of Conscientiousness called "Achievement striving" shows no such differences in the US. [1] Examples. McKellar has received some flak for her choice of examples: looking cute, boys, and looking cute for boys (with the occasional baking example). For instance, the ratio of lipglosses that one sister has to the lipglosses her sister has, or having girls list all the traits that each of their crushes has had and circling the ones in common ("their type") to introduce common factors. Even though the women featured in the book's testimonials talk about how they use math to speculate on foreign currencies for Wall St. firms, McKellar is not so clueless as to think that serious finance would appeal to girls who aren't even in high school. If their biology programs them to only have a few top priorities at that age, you're just going to have to deal with that constraint when trying to reach them. However, the author does not take such a cynical attitude toward young girls' concerns: she is glad that they are enthusiastic about femininity, and the examples show McKellar's unashamedly pro-girly stance where many a "women in science" activist would have treated young girls' priorities at best as outdated and in need of social re-engineering, and at worst as something the girls should feel embarrassed about. It's worth noting that all of the testimonials include pictures of the women: all are clearly above-average in physical attractiveness and enjoy dressing stylishly and making themselves up. Appropriateness. Well, obviously the book will bore and turn off the half of the teenage population that has a Y chromosome. Still, looking just at girls, McKellar has clearly written a book to benefit bright girls, and this should be kept in mind when recommending it for use. The author herself graduated summa cum laude from UCLA, co-authored a proof in mathematical physics, and though she is too modest to blab how high her SAT score was, she mentions that her sister got a "near perfect" score on the LSAT, attended Harvard Law School, and is a "high-powered lawyer" in New York City. Before UCLA, the author attended the elite Harvard-Westlake High School in Los Angeles. It shouldn't be any surprise that two sisters should correlate so highly in intelligence, given its moderate-to-strong heritability. Also, sprinkled throughout the book are testimonials from women who felt queazy about math in secondary school but who now use math every day at, for example, Manhattan investment banks. Conservatively, we may estimate the mean IQ of these women at 130, and more likely around 145 (or 2 to 3 standard deviations above the population mean of 100). These are the girls who will effortlessly assimilate the myriad tricks and strategies that McKellar provides -- anyone who thinks that merely expounding on a neat trick, and even walking the student through the trick using many examples, will cause them to learn it has never taught students of average or below-average IQ. Due to regression toward the mean and just chance, some children of bright parents end up mediocre in intelligence, and having tutored some of them, I can say that their parents' wealth and power can't do squat to make their kid smarter. Of course, if there is a proven IQ-booster (aside from, e.g., providing better nutrition to deprived children), it is a very well-guarded secret. To her credit, though, McKellar does not drape her work in the frippery of quixotic egalitarianism. Again, most of the testimonials are from very smart women, who we know were very smart to begin with, and who just needed to get over their mathphobia if they wanted a career in investment banking. I didn't keep score, but I believe that bourgeois professionals vastly outnumbered academics in these testimonials [2], something that McKellar does not feel apologetic about -- rightly, as most smart girls don't want to grow up to be nerds but "high-powered" professionals. As an aside, this freedom of choice for smart girls certainly accounts for some of the variance in the percentage of Nobel Prizes won by women in the pre- and post-women's liberation periods. Once women were allowed to enter the professions, they won fewer "hard" Nobel Prizes, indicating that some of the female scientists and mathematicians of the past would likely have preferred to practice medicine or law, but had no other choice than to conduct research. McKellar, her sister, and most of the women from the testimonials are cases-in-point: they are all great at math, yet only one has chosen a career as a research scientist. The author herself majored in math at a prestigious university, graduated summa cum laude, and shares credit for a math/physics proof -- how much more positive encouragement could she need if she truly wanted to be a research mathematician? She just prefers what more women than men prefer to do with their lives: to work more with people than objects, and to help and nurture more than to figure out how things work. Hence her career as an actress and tutor / life coach. One gripe I do have is that, even bearing in mind that only smart girls will benefit from the book, the very first topic treated is the prime factorization of integers -- something that would frighten away most smart adults who haven't seen math in awhile. Later she shows how to tease the greatest common factor of two integers out of their prime factorizations. Here I think McKellar's math nerdiness got the better of her: the most boring branch of math for most people, even math and science nerds, is number theory, and prime factorization offers little practical use in secondary school math to compensate. This could have the effect of scaring away some girls who would otherwise have pounded through the remainder of the book, which focuses appropriately on the basics of pre-algebra. In sum, don't take this book at face-value -- it's not going to solve an educational crisis, attract more than a handful of girls into research-based careers, and so on. Indeed, no book will be a philosopher's stone that alters human nature in that way. On the other hand, for what such a book is capable of, Math Doesn't Suck passes with flying colors. It is best suited to bright young girls who simply need a good kick in the rear to get them over their mathphobia. The tone and use of examples are excellent, bearing in mind who the real target audience is. And most importantly, for all of her outward feminism, McKellar -- as well as Tara Smith, a former cheerleader -- has laid the first stone along a route away from orthodox "women in science" activism. You can disagree with some of what they'd say, but you feel you are interacting with good-faith, rational human beings instead of someone whose emotions so overwhelm her thought processes that she would get nauseous and nearly faint upon hearing contrary viewpoints in a dispassionate discussion. So, who out there is going to write the companion volume for young boys? [1] See my review of the relevant meta-analysis here, appropriately enough in the context of women in science. [2] There was one student of neuroscience, and I think that was it. There was also a petroleum analyst. Labels: mathematics, Women in science
Saturday, July 07, 2007
Terrence Tao, recipient of a 2006 Fields medal, has a blog. I found this post on compressed sensing and image compression to be rather illuminating.
Labels: mathematics
Tuesday, May 22, 2007
Adaptive radiation in biology and academia: Why math matters
posted by
agnostic @ 5/22/2007 10:42:00 AM
The idea that a species will undergo diversifying selection as it begins to colonize an environment made up of many niches never seen before -- adaptive radiation -- is pretty intuitive. It's obvious enough qualitatively that you'd figure it out on your own if thinking about biology were your day job: the forms of life around us seem so different mostly because they are adapted to different habitats. That idea should probably scale down to sub-populations of a single species. What biologists get paid to do is flesh out the finer-grained quantitative details of how that happens, how much diversity will be maintained by what conditions, and so on. We talk a lot here about recent human evolution (that is, after the invention of agriculture), and so it's worth knowing some of the key points that emerge from quantitative studies of adaptive radiation.
Toward that end, here is a free journal article from PNAS by Gavrilets & Vose which has pointers to the lit and is brief / very readable (although if you want, you can skip their "model" and "methods" sections and focus on "results and interpretations" and "discussion"). Since it's pretty short, I'll let readers peruse it themselves rather than report its contents, but one thing's worth noting: speciation in their model occurred in huge initial bursts. This is yet more evidence that it's foolish to argue that natural selection "hasn't had enough time" to differentiate human populations within 10,000 years, since adaptation doesn't creep steadily. See also the review and simulation articles by H.A. Orr to this effect. Clearly, to the extent that we've moved from one form of society to another more quickly over this time period, these bursts are probably occurring more frequently than in pre-agricultural times. If anything, the only thing that there "hasn't been enough time for" is the settling down of the adaptive process toward a steady state. Now, the non-math-phobes will have noticed a few phrases lifted from math lingo in the previous paragraph -- the rate of change is increasing (acceleration), are we in a steady vs transient state, etc. But how many here -- not least of which is me -- would know what to do with the jargon of knots, braids, links, or anything else from the field of topology? The only incorporation of these kinds of ideas that I've seen is the chapter on evolutionary graph theory in Martin Nowak's Evolutionary Dynamics. Maybe there are similar articles or book chapters out there, but the point is that there is a mostly unsettled niche begging to be exploited by biologists whose math toolkit contains more than "engineering math" (i.e., non-expert levels of calculus & differential equations, linear algebra, and statistics & probability). That's no slight to knowing this much math -- but since these tools have been applied for so many decades, it makes it harder to create something original using them. If you were the first to learn, say, knot theory and apply it to biology, you'd blaze a new trail. Even if you personally didn't perform optimally in this area, your intellectual descendants would become increasingly adapted to it and really exploit it (you'd still get credit as the progenitor). Hell, you wouldn't even need to invent new math -- you could absorb what's already understood in math, and maybe roughly how it's used in applications (which would probably be in physics). All you'd have to do is use a bit of analogical reasoning to figure out what pattern in biology it looks like -- or perhaps predict a biological phenomenon that's currently not known, and investigate that. Edison didn't give much of a role to inspiration, but we could go farther and say that sometimes inspiration is 99% canny opportunism: taking already invented tools to excavate a virgin mine in your own neck of the woods. Most "big ideas" in evolutionary biology are like this: the diffusion equation to model the spread of alleles through a population, game theory to study altruism, extreme value theory to deal with a mutation more beneficial than all extant alleles, and so on. I'm just harping on topology because of a neat little pop-math book I just read called Knots (review by Derbyshire; review by knot theorist). You'd better start settling now, since the corresponding niche in physics appears very crowded, and many of them must feel pressure to migrate to biology where they'd find it much easier to make a name for themselves. Labels: Evolution, mathematics |
  Razib's Home Page GNXP Archives Interviews Blogroll Principles of Population Genetics Genetics of Populations Molecular Evolution Quantitative Genetics Evolutionary Quantitative Genetics Evolutionary Genetics Evolution Molecular Markers, Natural History, and Evolution The Genetics of Human Populations Genetics and Analysis of Quantitative Traits Epistasis and Evolutionary Process Evolutionary Human Genetics Biometry Mathematical Models in Biology Speciation Evolutionary Genetics: Case Studies and Concepts Narrow Roads of Gene Land 1 Narrow Roads of Gene Land 2 Narrow Roads of Gene Land 3 Statistical Methods in Molecular Evolution The History and Geography of Human Genes Population Genetics and Microevolutionary Theory Population Genetics, Molecular Evolution, and the Neutral Theory Genetical Theory of Natural Selection Evolution and the Genetics of Populations Genetics and Origins of Species Tempo and Mode in Evolution Causes of Evolution Evolution The Great Human Diasporas Bones, Stones and Molecules Natural Selection and Social Theory Journey of Man Mapping Human History The Seven Daughters of Eve Evolution for Everyone Why Sex Matters Mother Nature Grooming, Gossip, and the Evolution of Language Genome R.A. Fisher, the Life of a Scientist Sewall Wright and Evolutionary Biology Origins of Theoretical Population Genetics A Reason for Everything The Ancestor's Tale Dragon Bone Hill Endless Forms Most Beautiful The Selfish Gene Adaptation and Natural Selection Nature via Nurture The Symbolic Species The Imitation Factor The Red Queen Out of Thin Air Mutants Evolutionary Dynamics The Origin of Species The Descent of Man Age of Abundance The Darwin Wars The Evolutionists The Creationists Of Moths and Men The Language Instinct How We Decide Predictably Irrational The Black Swan Fooled By Randomness Descartes' Baby Religion Explained In Gods We Trust Darwin's Cathedral A Theory of Religion The Meme Machine Synaptic Self The Mating Mind A Separate Creation The Number Sense The 10,000 Year Explosion The Math Gene Explaining Culture Origin and Evolution of Cultures Dawn of Human Culture The Origins of Virtue Prehistory of the Mind The Nurture Assumption The Moral Animal Born That Way No Two Alike Sociobiology Survival of the Prettiest The Blank Slate The g Factor The Origin Of The Mind Unto Others Defenders of the Truth The Cultural Origins of Human Cognition Before the Dawn Behavioral Genetics in the Postgenomic Era The Essential Difference Geography of Thought The Classical World The Fall of the Roman Empire The Fall of Rome History of Rome How Rome Fell The Making of a Christian Aristoracy The Rise of Western Christendom Keepers of the Keys of Heaven A History of the Byzantine State and Society Europe After Rome The Germanization of Early Medieval Christianity The Barbarian Conversion A History of Christianity God's War Infidels Fourth Crusade and the Sack of Constantinople The Sacred Chain Divided by the Faith Europe The Reformation Pursuit of Glory Albion's Seed 1848 Postwar From Plato to Nato China: A New History China in World History Genghis Khan and the Making of the Modern World Children of the Revolution When Baghdad Ruled the Muslim World The Great Arab Conquests After Tamerlane A History of Iran The Horse, the Wheel, and Language A World History Guns, Germs, and Steel The Human Web Plagues and Peoples 1491 A Concise Economic History of the World Power and Plenty A Splendid Exchange Contours of the World Economy 1-2030 AD Knowledge and the Wealth of Nations A Farewell to Alms The Ascent of Money The Great Divergence Clash of Extremes War and Peace and War Historical Dynamics The Age of Lincoln The Great Upheaval What Hath God Wrought Freedom Just Around the Corner Throes of Democracy Grand New Party A Beautiful Math When Genius Failed Catholicism and Freedom American Judaism
Archives
July 2005 August 2005 September 2005 October 2005 November 2005 December 2005 January 2006 February 2006 March 2006 April 2006 May 2006 June 2006 July 2006 August 2006 September 2006 October 2006 November 2006 December 2006 January 2007 February 2007 March 2007 April 2007 May 2007 June 2007 July 2007 August 2007 September 2007 October 2007 November 2007 December 2007 January 2008 February 2008 March 2008 April 2008 May 2008 June 2008 July 2008 August 2008 September 2008 October 2008 November 2008 December 2008 January 2009 February 2009 March 2009 April 2009 May 2009 June 2009 July 2009 August 2009 September 2009 October 2009 November 2009 December 2009 January 2010 February 2010 Hello Movable Type archives August 11,2002 August 18,2002 August 25,2002 September 01,2002 September 15,2002 October 20,2002 December 08,2002 December 22,2002 December 29,2002 January 05,2003 January 12,2003 January 19,2003 January 26,2003 February 02,2003 February 09,2003 February 16,2003 February 23,2003 March 02,2003 March 09,2003 March 16,2003 March 23,2003 March 30,2003 April 06,2003 April 13,2003 April 20,2003 April 27,2003 May 04,2003 May 11,2003 May 18,2003 May 25,2003 June 01,2003 June 08,2003 June 15,2003 June 22,2003 June 29,2003 July 06,2003 July 13,2003 July 20,2003 July 27,2003 August 03,2003 August 10,2003 August 17,2003 August 24,2003 August 31,2003 September 07,2003 September 14,2003 September 21,2003 September 28,2003 October 05,2003 October 12,2003 October 19,2003 October 26,2003 November 02,2003 November 09,2003 November 16,2003 November 23,2003 November 30,2003 December 07,2003 December 14,2003 December 21,2003 December 28,2003 January 04,2004 January 11,2004 January 18,2004 January 25,2004 February 01,2004 February 08,2004 February 15,2004 February 22,2004 February 29,2004 March 07,2004 March 14,2004 March 21,2004 March 28,2004 April 04,2004 April 11,2004 April 18,2004 April 25,2004 May 02,2004 May 09,2004 May 16,2004 May 23,2004 May 30,2004 June 06,2004 June 13,2004 June 20,2004 June 27,2004 July 04,2004 July 11,2004 July 18,2004 July 25,2004 August 01,2004 August 08,2004 August 15,2004 August 22,2004 August 29,2004 September 05,2004 September 12,2004 September 19,2004 September 26,2004 October 03,2004 October 10,2004 October 17,2004 October 24,2004 October 31,2004 November 07,2004 November 14,2004 November 21,2004 November 28,2004 December 05,2004 December 12,2004 December 19,2004 December 26,2004 January 02,2005 January 09,2005 January 16,2005 January 23,2005 January 30,2005 February 06,2005 February 13,2005 February 20,2005 February 27,2005 March 06,2005 March 13,2005 March 20,2005 March 27,2005 April 03,2005 April 10,2005 April 17,2005 April 24,2005 May 01,2005 May 08,2005 May 15,2005 May 22,2005 May 29,2005 June 05,2005 June 12,2005 June 19,2005 June 26,2005 July 03,2005 July 17,2005 August 07,2005 Blogspot archives June 2002 July 2002 August 2002 September 2002 October 2002 November 2002 December 2002
10 questions for....
Parag Khanna James Flynn Jon Entine Gregory Clark György Buzsáki Heather Mac Donald Bruce Lahn A.W.F. Edwards Luigi Luca Cavalli-Sforza Joseph LeDoux Matthew Stewart Charles Murray James F. Crow Adam K. Webb Justin L. Barrett David Haig Judith Rich Harris Ken Miller Dan Sperber Warren Treadgold Armand M. Leroi John Derbyshire
Blogs
The GiveWell Blog Your Religion Is False Colby Cosh Steve Hsu Audacious Epigone Catallaxy Files Inductivist 2 Blowhards Genetic Future Agnostic Steve Sailer Dienekes Derek Lowe Razib Khan Razib at Comment is Free Secular Right Glenn Reynolds Jim Miller Kevin McGrew John Hawks Peter Fost Randall Parker Less Wrong Charles Murray Carl Zimmer EconLog Marginal Revolution
Principles of Population Genetics
Genetics of Populations Molecular Evolution Quantitative Genetics Evolutionary Quantitative Genetics Evolutionary Genetics Evolution Molecular Markers, Natural History, and Evolution The Genetics of Human Populations Genetics and Analysis of Quantitative Traits Epistasis and Evolutionary Process Evolutionary Human Genetics Biometry Mathematical Models in Biology Speciation Evolutionary Genetics: Case Studies and Concepts Narrow Roads of Gene Land 1 Narrow Roads of Gene Land 2 Narrow Roads of Gene Land 3 Statistical Methods in Molecular Evolution The History and Geography of Human Genes Population Genetics and Microevolutionary Theory Population Genetics, Molecular Evolution, and the Neutral Theory Genetical Theory of Natural Selection Evolution and the Genetics of Populations Genetics and Origins of Species Tempo and Mode in Evolution Causes of Evolution Evolution The Great Human Diasporas Bones, Stones and Molecules Natural Selection and Social Theory Journey of Man Mapping Human History The Seven Daughters of Eve Evolution for Everyone Why Sex Matters Mother Nature Grooming, Gossip, and the Evolution of Language Genome R.A. Fisher, the Life of a Scientist Sewall Wright and Evolutionary Biology Origins of Theoretical Population Genetics A Reason for Everything The Ancestor's Tale Dragon Bone Hill Endless Forms Most Beautiful The Selfish Gene Adaptation and Natural Selection Nature via Nurture The Symbolic Species The Imitation Factor The Red Queen Out of Thin Air Mutants Evolutionary Dynamics The Origin of Species The Descent of Man Age of Abundance The Darwin Wars The Evolutionists The Creationists Of Moths and Men The Language Instinct How We Decide Predictably Irrational The Black Swan Fooled By Randomness Descartes' Baby Religion Explained In Gods We Trust Darwin's Cathedral A Theory of Religion The Meme Machine Synaptic Self The Mating Mind A Separate Creation The Number Sense The 10,000 Year Explosion The Math Gene Explaining Culture Origin and Evolution of Cultures Dawn of Human Culture The Origins of Virtue Prehistory of the Mind The Nurture Assumption The Moral Animal Born That Way No Two Alike Sociobiology Survival of the Prettiest The Blank Slate The g Factor The Origin Of The Mind Unto Others Defenders of the Truth The Cultural Origins of Human Cognition Before the Dawn Behavioral Genetics in the Postgenomic Era The Essential Difference Geography of Thought The Classical World The Fall of the Roman Empire The Fall of Rome History of Rome How Rome Fell The Making of a Christian Aristoracy The Rise of Western Christendom Keepers of the Keys of Heaven A History of the Byzantine State and Society Europe After Rome The Germanization of Early Medieval Christianity The Barbarian Conversion A History of Christianity God's War Infidels Fourth Crusade and the Sack of Constantinople The Sacred Chain Divided by the Faith Europe The Reformation Pursuit of Glory Albion's Seed 1848 Postwar From Plato to Nato China: A New History China in World History Genghis Khan and the Making of the Modern World Children of the Revolution When Baghdad Ruled the Muslim World The Great Arab Conquests After Tamerlane A History of Iran The Horse, the Wheel, and Language A World History Guns, Germs, and Steel The Human Web Plagues and Peoples 1491 A Concise Economic History of the World Power and Plenty A Splendid Exchange Contours of the World Economy 1-2030 AD Knowledge and the Wealth of Nations A Farewell to Alms The Ascent of Money The Great Divergence Clash of Extremes War and Peace and War Historical Dynamics The Age of Lincoln The Great Upheaval What Hath God Wrought Freedom Just Around the Corner Throes of Democracy Grand New Party A Beautiful Math When Genius Failed Catholicism and Freedom American Judaism   Policies Terms of use © http://www.gnxp.com Razib's total feed: |