I was recently recommended an excellent book with the irresistibly seductive title The Geometry of Multivariate Statistics, which offers more visually oriented people a crisp way of thinking about statistics that still captures what the algebraic formulas say. To be sure, the author is aware that diagrams, pictures, and so on are employed anytime someone draws a histogram, but he seeks to ground the gamut of the most important ideas in statistics — variance, correlation, regression, and so on — in a geometric view, focusing mostly on vectors and trigonometry.
I have found this 160-page book to be quite helpful in fully wrapping my brain around the core ideas of statistics*, although it is best used in conjunction with a standard textbook containing the algebraic and computational sides of things. It would also help to read it after or concurrent with a first course in linear algebra: while there is no use of eigenvalues / eigenvectors or matrix algebra, you should be familiar with the basic idea of what vectors and vector spaces are (though some complain that many students memorize the matrix algorithms without “getting” the more basic ideas). The book does provide an overview of these fundamentals, but it is more of a reminder.
Both to share this exciting new way of looking at statistics, as well as to help me get a solid lock on the perspective, I thought I’d give a little taste of what the book has to offer. Unfortunately, I’ll be using fake data since I don’t have enough time to collect my own or search for that of others, but the goal here is more didactic than empirical. Caveat: anyone who’s already read the book or studied statistics in this way will be pretty bored by this post.
Background
The basic idea is that, unlike when we graph scatter-plots, which plot (in variable-space) how various subjects scored on different variables — say, height and weight — we’re going to plot the variables themselves in “subject-space,” to see directly how the variables relate to one another (since usually we don’t care about the subjects themselves except as a way to figure out the relationships between the variables). For instance, let’s say we tested two subjects on their height and weight, such that the height in inches and weight in pounds (respectively) for subjects A, B, and C were (69, 135), (72, 150), and (79, 200). In a scatter-plot, we’d have 2 axes (height and weight) and 3 data-points corresponding to the 3 subjects.
Standing this view on its head, let’s instead create a 3-D graph with one axis for each of the 3 subjects, and just 2 data-points (one for height, one for weight). The height data-point would “score” 69 on the A-axis, 72 on the B-axis, and 79 on the C-axis. The weight data-point would “score” 135, 150, and 200 on these axes, respectively. So then, our new data-points (69, 72, 79) and (135, 150, 200) are just vectors whose components are the heights and weights of all the subjects. Instead of trying to infer the properties of and relationships between the height and weight variables from a scatter-plot, we can see them more directly by examining the magnitude of the vectors and the angle between them.
Notice that if we center each variable by subtracting the mean from each component, the new vector’s components are deviations from the mean. Consider two such centered vectors x and y. If we take the dot product of x with itself, we get the sum of the squares of each component. And since the components are deviations from the mean, x dot x is equal to the variance; square-rooting this gives us the standard deviation. Now, recall the following dot product formula for the angle between x and y:
cos(x, y) = (x dot y) / (|x| times |y|)
Since any vector is collinear with itself, the angle between “them” is 0, making the cosine 1. If both vectors on the right-hand side of the equation are the same, then x dot x must equal |x| times |x| or |x|^2 to make the ratio equal 1. Because in our case x dot x equals the variance of the variable it represents, then the variance also equals the square of the length or magnitude of the vector. Thus, the length itself equals the square-root of the variance, or standard-deviation. That’s a pretty neat way to see how spread out the values of a variable are: just look at how long the vector representing it is.
As for their correlation, refer to MathWorld’s entry on the correlation coefficient, specifically line 22 (the notation for sum of squares, SS, is defined in the first 9 lines). Square-root both sides to get r by itself. Since we’ve centered our variables, we could re-write the formula as:
r = (x dot y) / (|x| times |y|)
Of course, that’s equal to the cosine of the angle between x and y, so taking the inverse-cosine of the ratio on the right-hand side gives us the correlation coefficient. Thus, the larger the cosine — and so, the smaller the angle — the larger the correlation. That makes it an easy task to see the correlation: draw the vectors from the same point and look at the angle formed between them.
An example
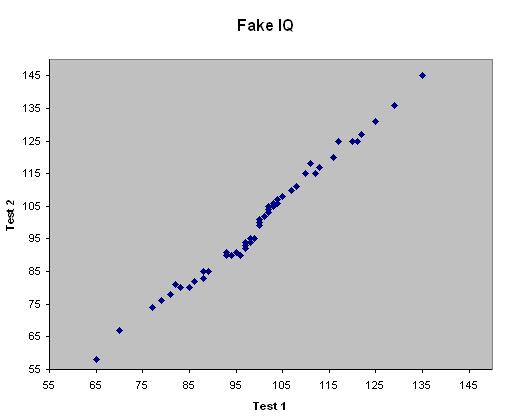
So, let’s take a look at how this might play out in the real world. Suppose we test 50 people on two distinct IQ tests and create a scatter-plot of an individual’s score on Test 1 and Test 2. It might look something like this (again, this is fake data for illustration):
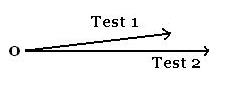
Let’s just focus on two aspects of the data, the correlation between scores and the variance in scores for each test. Clearly, there is a high correlation between scores, as we’d expect if IQ tests measure pretty much the same underlying construct (general intelligence). As a correlation always lies in [-1, 1], eyeballing the correlation from a scatter-plot forces you to judge angles that range from 0 to 45 degrees in magnitude. When we redraw the two variables as vectors, however, the angle between them (which again indicates the correlation) can range from 0 to 90 degrees in magnitude, which places less stringent demands on our visual acuity to get the gist of the picture. Judge for yourself (this shows the centered variables, but the correlation between them and their variances are unaffected by translating the mean to 0):
Even as a more visually oriented person, I find the small ang
le between the vectors (~6.9 degrees) easier to grok than the discrepancy of the trend-line’s slope from +/- 1. Turning now to the variance in scores, it’s not so clear from the scatter-plot which test has greater variance — to my eye, it looks wider than taller, suggesting Test 1 has greater variance, but this is wrong. In fact, the standard deviations for Test 1 and 2 are 14.6 and 18.3, respectively. I suspect my misjudging the spread of the two variables on the scatter-plot is due to a bias of the human visual system that finds horizontal lines longer than vertical lines of equal length, but who knows? Returning to the vector picture above, it is immediately clear that the Test 2 vector is longer than that of Test 1, indicating greater variability. Since Test 2’s SD is 18.3 / 14.6 = 1.25 times larger than that of Test 1, the corresponding vector is 1.25 times longer. Admittedly, if the variables were close to uncorrelated — and so, if the vectors were nearly orthogonal — the task of judging their respective lengths would be a bit more difficult than when they’re more closely related, but most of the interesting results that people have to share are when there is at least a weak or modest correlation between variables.
So that’s it, really — not a difficult viewpoint to understand, but I find it much more illuminating than a raw algebraic derivation of formulas. Remember that this way of thinking is no less formal or rigorous, but just taps into a different modality of thinking, which some find more natural. There is a lot more in the book (regression, ANOVA, and more), so I hope this brief post has piqued your curiosity enough to at least browse through it in your library. It’s not very long either, so why not add it to your list of must-reads?
*I started studying stats way back in high school when I took AP Statistics, so I’m no stranger to the subject. Still, the (to me) novel appeal to geometric reasoning makes a lot of it pretty intuitive now. One of the reviews at the Amazon entry claims that a lot of early work in statistics was guided by geometry, which, not being a statistician, I was unaware of — though given that the inveterate geometer R.A. Fisher pioneered a lot of modern statistics, it’s not surprising to hear.
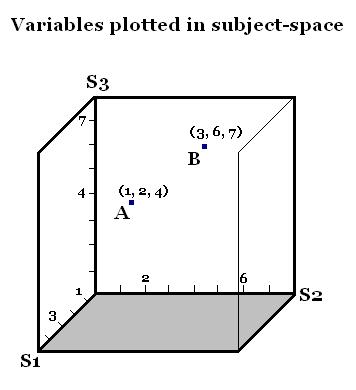
Addendum: By request, here are pictures that show the difference between plotting subjects as points in variable-space (a familiar scatter-plot) and plotting the variables as vectors in subject-space. Subject 1 scores 1 on Variable A and 3 on Variable B, so his data-point is (1, 3), and likewise for the other two Subjects.
To plot the Variables themselves, we gather their values across all three Subjects — so Variable A “scores” 1 on Subject 1 (since that is S1’s value on A), 2 on Subject 2, and 4 on Subject 3; likewise for Variable B.
The idea is to draw a vector a from the origin to (1, 2, 4) and b to (3, 6, 7). I omitted these lines since it would clutter the picture, but you can see that they point in pretty similar directions, which here means that they’re highly correlated. In fact, the cosine between them is 0.968 — their correlation.
If you measured the same 2 Variables but included data from 100 Subjects, it’s obviously impractical to try to draw a 100-dimensional coordinate grid just to plot the two vectors representing the variables. But since you can draw the length of a vector according to its SD, and draw an angle between them to indicate their correlation, you don’t really need 100 dimensions to see how the Variables relate. The simpler 3-D picture above is to illustrate the rationale: represent a Variable as a vector whose components are the scores on that Variable across all the Subjects tested.

 So, I tried out
So, I tried out 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}