History of Japan is a good survey for anyone curious about the topic because it is short enough to not be intimidating (this was a complaint from friends who I recommended read The Making of Modern Japan), but dense enough to actually be much more informative than a Wikipedia entry. Unlike many surveys of Japanese history, it does not operationally begin with Oda Nobunaga. The extensive treatment of the Nara and Heian period is something that I particularly appreciated since often these are explored only in specialist monographs with any depth.
History of Japan is a good survey for anyone curious about the topic because it is short enough to not be intimidating (this was a complaint from friends who I recommended read The Making of Modern Japan), but dense enough to actually be much more informative than a Wikipedia entry. Unlike many surveys of Japanese history, it does not operationally begin with Oda Nobunaga. The extensive treatment of the Nara and Heian period is something that I particularly appreciated since often these are explored only in specialist monographs with any depth.
One of the curious things about Japan is that since the conquest of the Emishi of northern Honshu around 800 AD, the Japanese lost an external frontier with another people. True, there were periods of endemic warfare between Japanese when central authority collapsed, but by and large, these conflicts were arguably less destructive than shocks from without would have been. Wars within cultural groups are highly destructive, but often they are governed by unified cultural scripts and mores.
 In Strange Parallels: Mainland Mirrors: Europe, Japan, China, South Asia, and the Islands, the historian Victor Lieberman examines Japan as a case study of a “protected-zone” civilization. In Lieberman’s framework, the emergence of organized steppe nomadism in the years after the fall of Rome and China caused stress and chaos across what Nichols Spyman would term the “Eurasian rimland,” and what the ancients would have termed the civilized oikoumene. The same model crops up in Ian Morris’ War! What Is It Good For?: Conflict and the Progress of Civilization from Primates to Robots.
In Strange Parallels: Mainland Mirrors: Europe, Japan, China, South Asia, and the Islands, the historian Victor Lieberman examines Japan as a case study of a “protected-zone” civilization. In Lieberman’s framework, the emergence of organized steppe nomadism in the years after the fall of Rome and China caused stress and chaos across what Nichols Spyman would term the “Eurasian rimland,” and what the ancients would have termed the civilized oikoumene. The same model crops up in Ian Morris’ War! What Is It Good For?: Conflict and the Progress of Civilization from Primates to Robots.
The development of the chariot during the Bronze Age was arguably an integrative force in the evolution of agricultural polities. Chariots were useful for the transport and deployment of elite warriors and archers. But, they were not utilized as shock troops, as would be the case with the rise of mounted cavalry. First emerging around 1000 BC on the western edge of the Eurasian steppe, by 0 AD the mounted cavalry had given birth to full-blown nomadism from Europe to China. To some extent, the only way that core civilizations on the Eurasian rimland could maintain themselves in the face of the pure nomadic assault was through co-option and assimilation. Arabs, Turks, and Mongols all swallowed up earlier settled civilizations. In the Near East, China, and India, peoples of nomadic origin became the ruling classes, synthesizing and integrating with the traditions of those they conquered.
 In contrast, much of Western Europe and Southeast Asia were protected from these incursions due to distance, topography, and climate. The German barbarians who took over the reins of power in the post-Roman world were agro-pastoralists, not nomads. In mainland Southeast Asia, the Tai incursions was a migration of agriculturalist warrior elites. The modern states of Cambodia, Vietnam, and Burma withstood the assaults and maintained cultural continuity with their past. In Western Europe, Ireland can be thought of as an analogous case, though the Viking shocks, and later Anglo-Normand conquest, disrupted its continuity.
In contrast, much of Western Europe and Southeast Asia were protected from these incursions due to distance, topography, and climate. The German barbarians who took over the reins of power in the post-Roman world were agro-pastoralists, not nomads. In mainland Southeast Asia, the Tai incursions was a migration of agriculturalist warrior elites. The modern states of Cambodia, Vietnam, and Burma withstood the assaults and maintained cultural continuity with their past. In Western Europe, Ireland can be thought of as an analogous case, though the Viking shocks, and later Anglo-Normand conquest, disrupted its continuity.
Lieberman argues in Strange Parallels that these protected-zone societies are much more natural nation-states than elsewhere, in part because their organic identity from earlier cultural traditions persisted down to the modern era, as opposed to having been created anew through novel ideologies. And is it a surprise that of the European nations England, which has not undergone a mass invasion since 1066*, has one of the deepest self-conceptions as a nation-state?
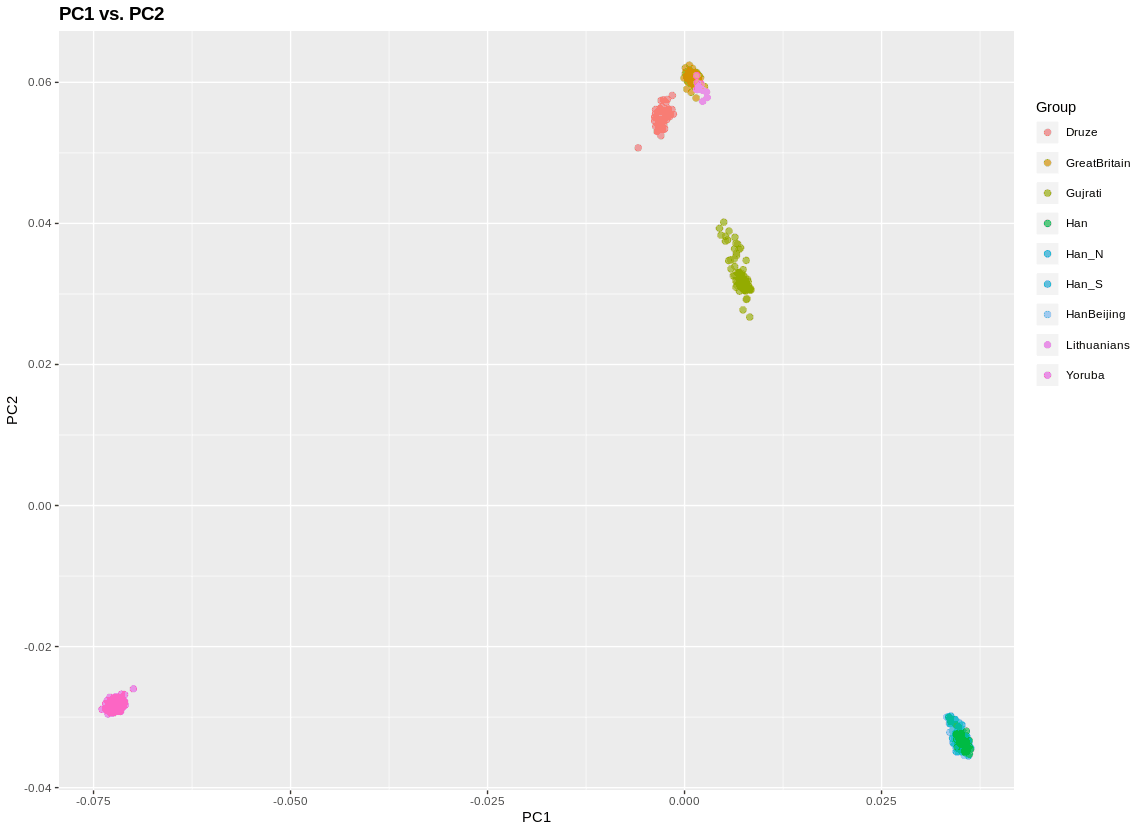
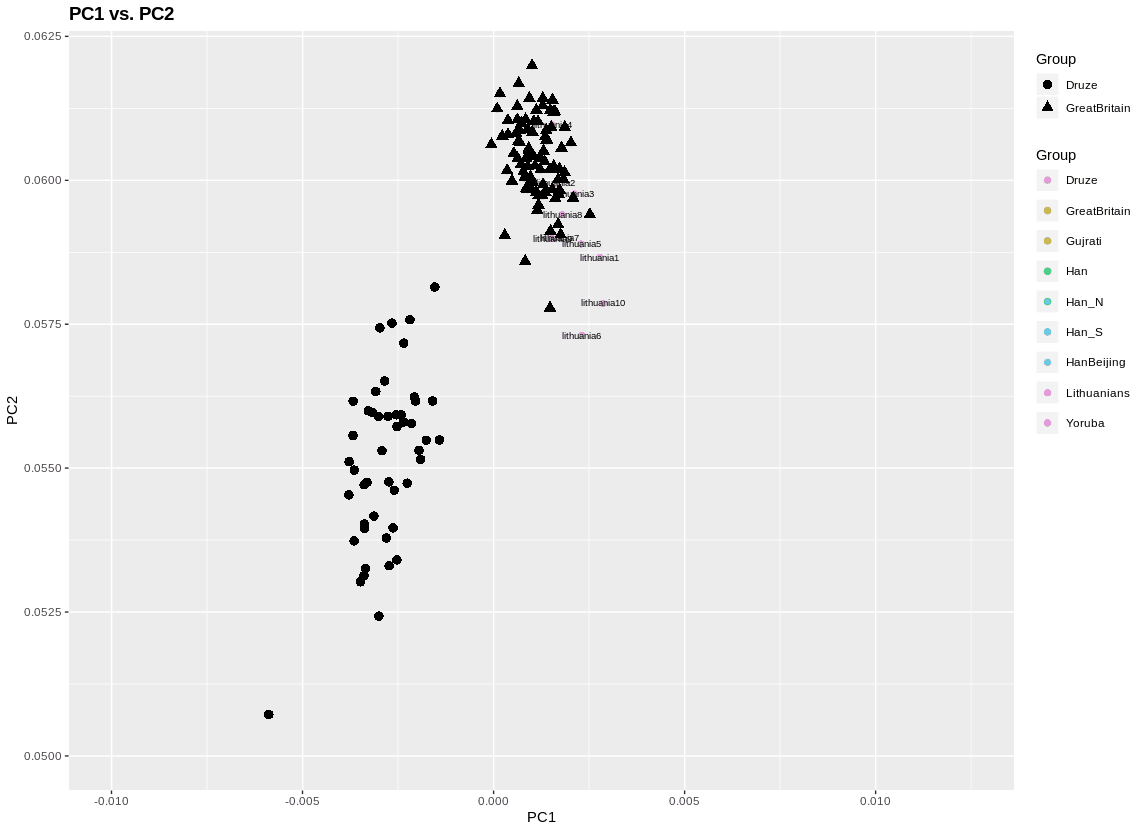
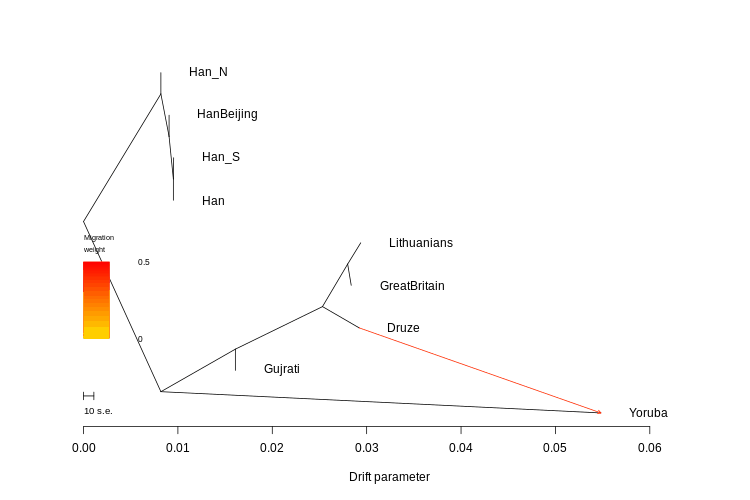
Which brings us back to Japan: its imperial family dates at least the early 6th century AD. Though we don’t have verified dates before the Emperor Kinmei, it seems likely that the Imperial House of Yamato is quite a bit older than that. Unlike in the West then the Japanese have a much easier line of descent from antiquity for its elites. The persistence of the Japanese imperial family is a testament to the cultural prominence that the Yamato lineage has, with all of its ups and downs. In contrast, the arrival of waves of barbarians in other regions of the Eurasian rimlands produces a situation where taboos against taking official power eventually broke down. In the 5th century West Roman Empire, there was a taboo against barbarians or people of part-barbarian ancestry from becoming Emperor. Eventually, the barbarians got rid of the Emperor, and over the centuries became Emperors themselves. The same process is evident in the Islamic world, where the Arab Caliphs remained figureheads for Persian and Turkic potentates until they took over both de jure and de facto roles.
 The Japanese have a different experience. At the beginning of their history, they were a cohesive culture expanding into the post-Jomon frontier. Though reinforced with an elite migration of Koreans and Chinese prior to the Fujiwara period, unlike polities across Eurasia the Japanese ruling class have been uniformly and continuously of the same ethnicity and identity as the populace which it ruled.** And, unlike the Vietnamese or Koreans, they have not been subjected to conquest and hegemony by China. They have long been of the Sinic sphere, not within the Sinic sphere.
The Japanese have a different experience. At the beginning of their history, they were a cohesive culture expanding into the post-Jomon frontier. Though reinforced with an elite migration of Koreans and Chinese prior to the Fujiwara period, unlike polities across Eurasia the Japanese ruling class have been uniformly and continuously of the same ethnicity and identity as the populace which it ruled.** And, unlike the Vietnamese or Koreans, they have not been subjected to conquest and hegemony by China. They have long been of the Sinic sphere, not within the Sinic sphere.
Between Korea and Japan, there is a 200 km distance by water. In contrast, between England and France, there are about 30 km. This greater distance explains the relative isolation of Japan in comparison to England when it comes to continental affairs. Proto-historical expeditions in Korea, or Hideyoshi’s adventure, are exceptions, not the rule. Official contacts between Japan and China often had gaps of centuries.
This is not to say that Japan was not influenced by the continent. Obviously, Buddhism, Chinese writing, and the wholesale transplantation of Tang culture during the Fujiwara period attest to the early influences, while later on even during the Tokugawa era there were influences from Western thought via the Dutch. Rather, the Japanese are a natural experiment of a people who have repeatedly engaged with the world on their own terms, and developed their own culture organically to such an extent that they put their ancient tribal animism, Shinto, as the state religion during their phase of modernization!
In answer to the question “why is Japan different?” I would say this is a peculiarity of geography, close enough to be influenced culturally, but distant enough to be politically isolated.
* I think the Dutch invasion under William of Orange really was an invasion. But its impact was mild due to broad local support.
** Contrast this with ethnically distinct ruling elites in the Near East, India, and China, as well as cosmopolitan ruling families in Europe. Even England was for several centuries ruled by a nobility which spoke French.