
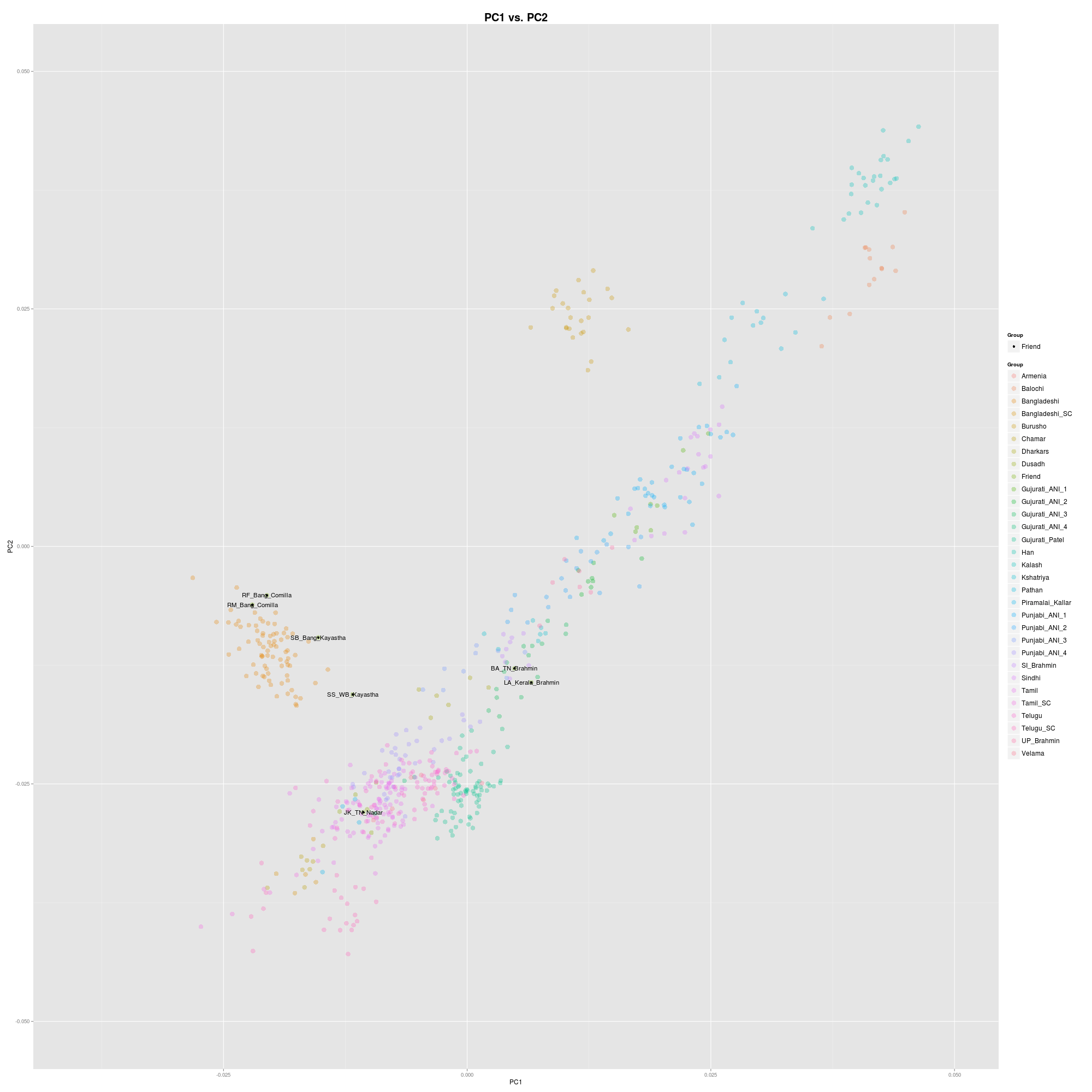
 For a while I’ve been playing around with 1000 Genomes South Asian data. It’s an interesting exercise, because unlike other South Asian data set it’s relatively generic with minimal ethnic/caste labels. This is important because unlike other population groups that the 1000 Genomes has sampled, such as in Africa, Europe, and East Asia, the South Asian data exhibit genetic structure beyond their ethno-linguistic identity. For example, the “Telugu” and “Tamil” data in the 1000 Genomes both contain individuals who are clearly Brahmins. This is obvious because these individuals are positioned on the margins of northern South Asian groups, not their ethno-linguistic compatriots. So using a combination of Estonion Biocentre data, the HGDP, and some friends and my own family, I’ve partitioned the 1000 Genomes South Asians more finely than is presented in the raw downloads.
For a while I’ve been playing around with 1000 Genomes South Asian data. It’s an interesting exercise, because unlike other South Asian data set it’s relatively generic with minimal ethnic/caste labels. This is important because unlike other population groups that the 1000 Genomes has sampled, such as in Africa, Europe, and East Asia, the South Asian data exhibit genetic structure beyond their ethno-linguistic identity. For example, the “Telugu” and “Tamil” data in the 1000 Genomes both contain individuals who are clearly Brahmins. This is obvious because these individuals are positioned on the margins of northern South Asian groups, not their ethno-linguistic compatriots. So using a combination of Estonion Biocentre data, the HGDP, and some friends and my own family, I’ve partitioned the 1000 Genomes South Asians more finely than is presented in the raw downloads.
The PCA above is hard to make out because there are so many groups I relabeled. But I’ve put the pedigree file (with my friends removed) with new labels on Dropbox. The Gujurati and Punjabi populations I separated by “ANI-ness,” from most to least numerically (Gujurati_ANI_1 is the most ANI for example). The large number of Patels I labeled separately, as they are pretty obvious (Zack Ajmal found that Patels for the Harappa project land right in the middle of this cluster of related individuals). Additionally, the Tamil and Telugu and Bangladeshi population had individuals who seem likely to have been scheduled caste or Dalit. I broke them out. I also removed a few outliers (e.g., one of the Telugu individuals was probably mixed caste, half-Brahmin and half non-Brahmin, so I removed them, and one of the Bangladeshis was likely a Bengali Brahmin or some such thing).
Some surprises for me in the 1000 Genomes. The “Punjabis” sampled from Lahore were very diverse. Many were clustering with Pathans in the HGDP (by the way, there were two Pathan clusters, so that I suspect that one of them is “Pathanized,” and I removed these). But there were others, such as Punjabi_ANI_4, who were not that different from more generic South Asians. I suspect these are Muhajirs who have become ethnically assimilated more or less (or, the 1000 Genomes just labeled everyone from Lahore as Punjabi). The Bangladeshis were ancestrally very homogeneous. Unlike the Tamils or Telugu speakers there wasn’t much of a separation of lower caste individuals, and not many were Brahmins either (I found one). There were a few individuals who were very distinct in the Bangladesh sample…they clustered with scheduled castes, and didn’t have much East Asian ancestry. I believe these people descend from migrants from India in the past few centuries because of the last fact and likely remain Hindu and maintain caste endogamy (two of them had adjacent IDs, so were probably sampled together?).
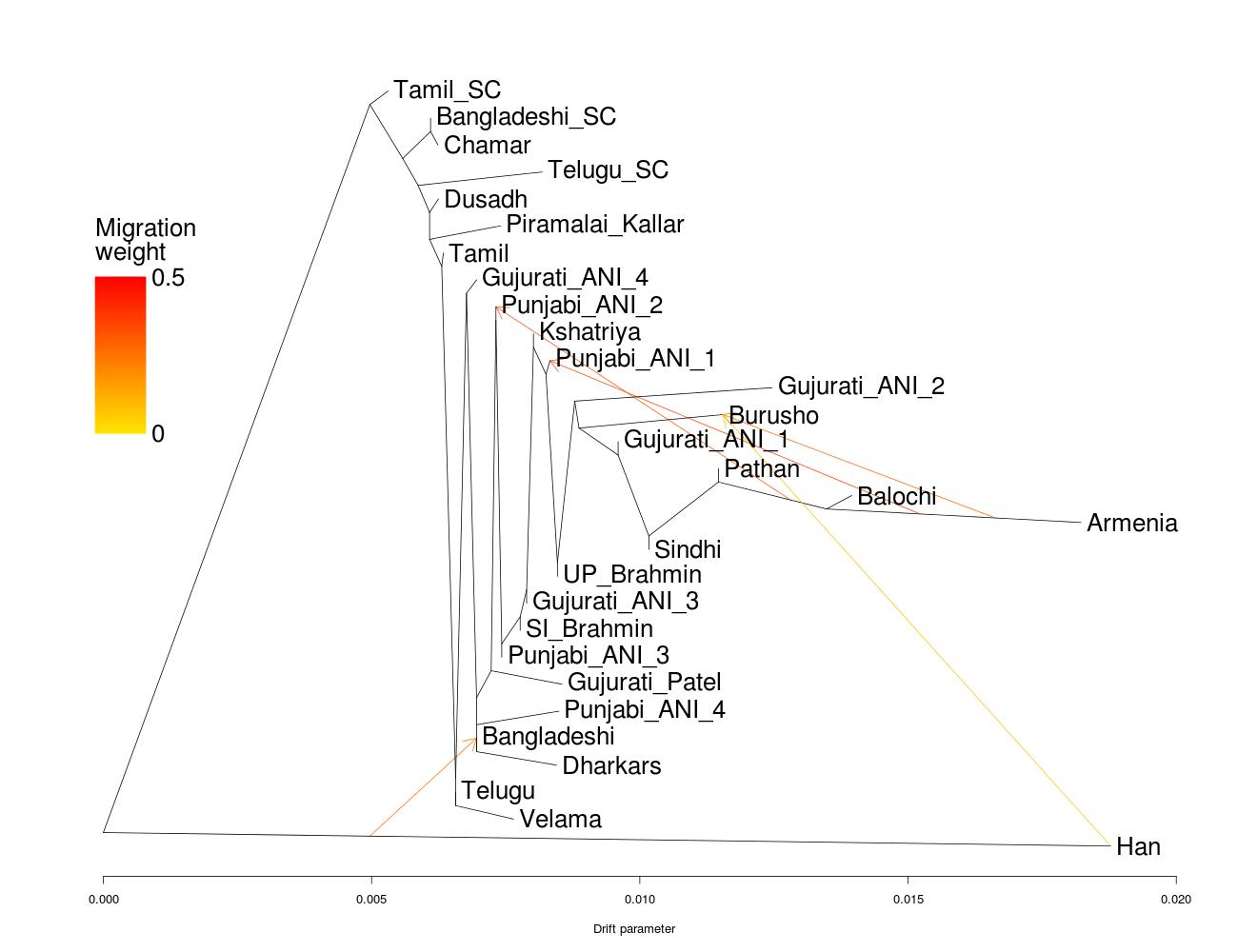 To the right is a representative TreeMix (you see all the rest on Dropbox). The Bangladeshi scheduled caste individuals are in the tree next to Chamars, Dalits from North India. The Telugu sample in the 1000 Genomes is most similar to Velamas, who I got from the Estonian Biocentre data set. Velamas are middle castes from Andhra Pradesh, so probably representative of the group that the 1000 Genomes Telugus are sampled from. The Bangladeshi samples are somewhat near the Patels or Gujurati_AN_4 in most of the runs, but have substantial East Asian ancestry. On the PCA above my parents, who are both from an eastern region of East Bengal, Comilla, are among the most East Asian of the Bangladeshis sampled. I also projected a friend whose family has deep roots in West Bengal and are Kayasthas. You can see that he is exactly between the Bangaldeshis and other South Asians. This suggests that the East Asian cline in Bengal is very sharp. It does not really persist outside of that region. Additionally, the idea that there is widespread Austro-Asiatic ancestry in South Asia does not seem to be supported by these data…only Bengalis and Burusho, both with notable East Asian ancestry, are shifted toward East Asians. The ANI-ASI cline is really sufficient for everyone else.
To the right is a representative TreeMix (you see all the rest on Dropbox). The Bangladeshi scheduled caste individuals are in the tree next to Chamars, Dalits from North India. The Telugu sample in the 1000 Genomes is most similar to Velamas, who I got from the Estonian Biocentre data set. Velamas are middle castes from Andhra Pradesh, so probably representative of the group that the 1000 Genomes Telugus are sampled from. The Bangladeshi samples are somewhat near the Patels or Gujurati_AN_4 in most of the runs, but have substantial East Asian ancestry. On the PCA above my parents, who are both from an eastern region of East Bengal, Comilla, are among the most East Asian of the Bangladeshis sampled. I also projected a friend whose family has deep roots in West Bengal and are Kayasthas. You can see that he is exactly between the Bangaldeshis and other South Asians. This suggests that the East Asian cline in Bengal is very sharp. It does not really persist outside of that region. Additionally, the idea that there is widespread Austro-Asiatic ancestry in South Asia does not seem to be supported by these data…only Bengalis and Burusho, both with notable East Asian ancestry, are shifted toward East Asians. The ANI-ASI cline is really sufficient for everyone else.
 Finally, I wanted analyze inbreeding in the South Asian samples. I used plink’s default run of homozygosity feature. The raw results are in the first Dropbox link. I invite you to check them out yourself. Looking to the left you see total runs of homozygosity in KB units across the genome. Notice that the Gujurati Patels are shifted to the right, but they have a narrow window. In contrast, the Bangladeshis are to the left, but have a few outlier individuals. The Patels are an endogamous Hindu group, and so likely have lots of medium length IBD tracts. But they don’t engage in marriage between close relations. In contrast, the Bangladeshis don’t seem to have practiced much endogamy at all, presumably because they’re Muslims and caste consciousness is weak among Bangladeshis from what I can tell (my family has very vague awareness by surnames what castes they were from, but no one really cares), but some of them engage in marriage between close kin.
Finally, I wanted analyze inbreeding in the South Asian samples. I used plink’s default run of homozygosity feature. The raw results are in the first Dropbox link. I invite you to check them out yourself. Looking to the left you see total runs of homozygosity in KB units across the genome. Notice that the Gujurati Patels are shifted to the right, but they have a narrow window. In contrast, the Bangladeshis are to the left, but have a few outlier individuals. The Patels are an endogamous Hindu group, and so likely have lots of medium length IBD tracts. But they don’t engage in marriage between close relations. In contrast, the Bangladeshis don’t seem to have practiced much endogamy at all, presumably because they’re Muslims and caste consciousness is weak among Bangladeshis from what I can tell (my family has very vague awareness by surnames what castes they were from, but no one really cares), but some of them engage in marriage between close kin.
 The second shows average length of the run of homozygosity, so is more informative of recent inbreeding. You can see that the Tamils have a flat distribution, because of lots of people who have long runs. Cousin marriage and uncle-niece marriage has been practiced by South Indian Hindus historically. The Punjabi samples also have long runs of homozygosity. One difference between Muslims in Pakistan and Muslims in Bangladesh seems to be that the Middle Eastern pattern of cousin marriage is much more ubiquitous in Pakistanis. I have no idea why there is this difference. Also, unlike Hindus in much of South Asia Bangaldeshis seem to exhibit little community level genetic structure. The thesis of Islam on the Bengal Frontier, that the strength of Islam in this region of Bengal was due to its relatively recent settlement and organization during the Muslim period, and that it was a unstructured frontier society, seems roughly supported by these genetic results.
The second shows average length of the run of homozygosity, so is more informative of recent inbreeding. You can see that the Tamils have a flat distribution, because of lots of people who have long runs. Cousin marriage and uncle-niece marriage has been practiced by South Indian Hindus historically. The Punjabi samples also have long runs of homozygosity. One difference between Muslims in Pakistan and Muslims in Bangladesh seems to be that the Middle Eastern pattern of cousin marriage is much more ubiquitous in Pakistanis. I have no idea why there is this difference. Also, unlike Hindus in much of South Asia Bangaldeshis seem to exhibit little community level genetic structure. The thesis of Islam on the Bengal Frontier, that the strength of Islam in this region of Bengal was due to its relatively recent settlement and organization during the Muslim period, and that it was a unstructured frontier society, seems roughly supported by these genetic results.
A final thing I should note is that I appreciate the Estonian Biocentre releasing it raw data, but many of the samples seem to exhibit little co-ethnic association. I’m not sure whether this is a labeling problem or something else, but I discarded a lot of individuals (e.g., a Uttar Pradesh Brahmin placed among non-Brahmin South Indians). But for the South Asians people should be cautious about using this data set without double checking (in contrast, the non-South Asians have never caused me this problem from that data set).
Anyway, please download the data and use it if useful. The IDs are the same you would recognize in the 1000 Genomes and HGDP etc. I put an ADMIXTURE file in there too for K = 4. Nothing surprising.
Comments are closed.