

 Since people asking me about this, and I’m running the South Asian Genotype Project, I thought I would post two non-PCA visualizations of how various South Asian groups relate to each other (along with a few outgroups).
Since people asking me about this, and I’m running the South Asian Genotype Project, I thought I would post two non-PCA visualizations of how various South Asian groups relate to each other (along with a few outgroups).
The radial plot above is a neighbor-joining tree visualized from pairwise Fst statistics (basically a proxy for genetic distance).
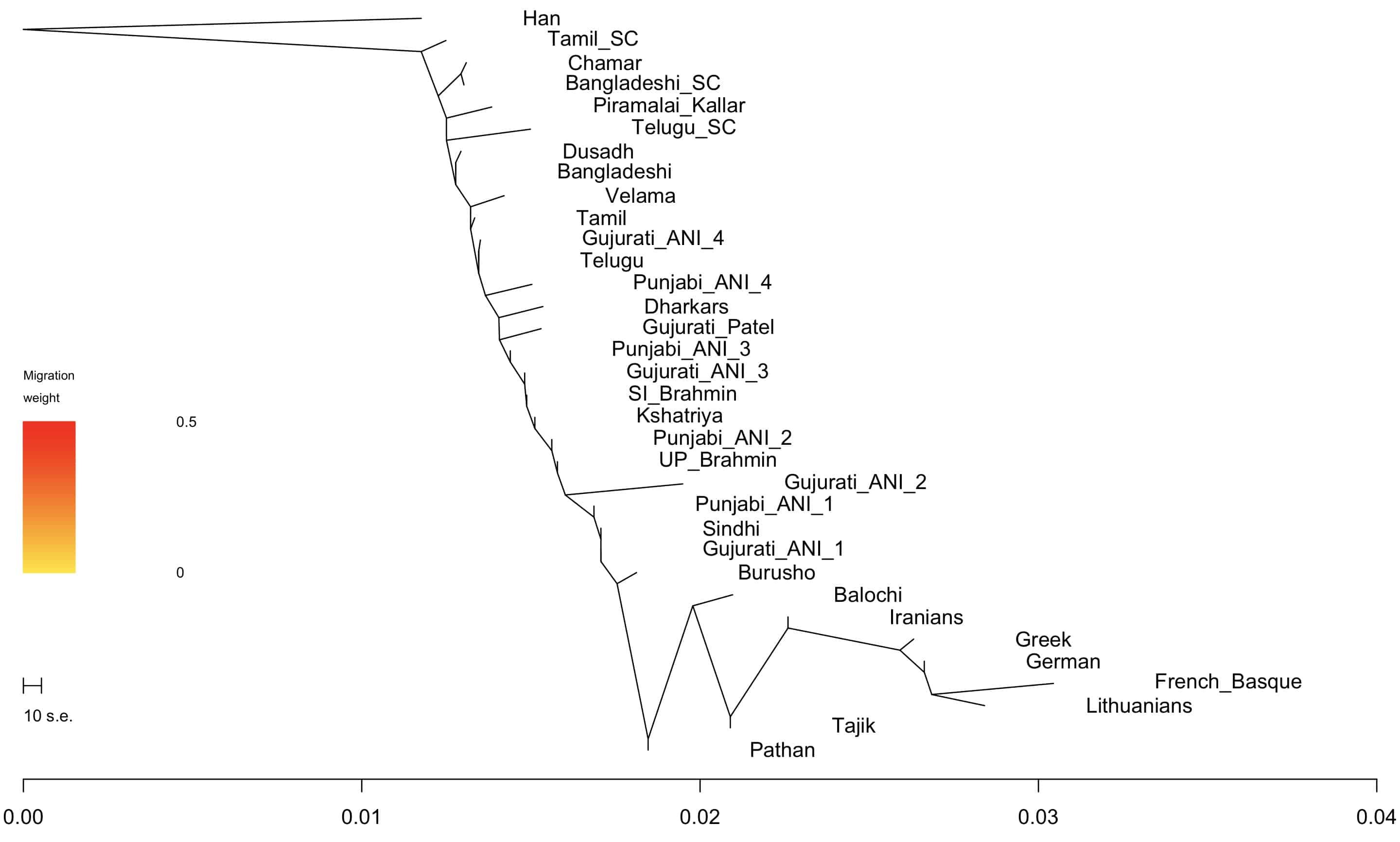
I also used Treemix to generate a plot. You see the similar patterns as the one above, though the two methods are different. Treemix tests a bunch of models and sees how the data fit those models. The visualization of Fst is just a way of representing the summary statistic.
 I added 5 migration edges to the plot to the right. Not sure if they add anything, but you can see that some of the nodes move around because they are so mixed.
I added 5 migration edges to the plot to the right. Not sure if they add anything, but you can see that some of the nodes move around because they are so mixed.
Is “Han” Han Chinese? Is that circular tree saying that Greeks and Han are more closely related to each other than either is to Iranians?
I see that the non-circular graphs appear to show “Han” as a distant outgroup to everybody else. What’s happening in the first one where Han are deeply embedded within a “European” taxon?
And, um, why does the circular tree have a root with three children, when as far as I see all other nodes (in the circular graph or in the other two) have two children?
(Sorry for the double comment; I was trying to edit the first one but ended up posting this duplicate instead.)
Would you mind uploading your Fst table so that I can have a look at it directly? thanks.
Michael Watts, I raised my eyebrows at the odd positioning of “Han” on the circular tree as well; but trees being what they are, the part to look at is the branching, not the horizontal position. You can rotate the Han and European branches round so that Han is the outlier just as well, so there isn’t a contradiction between that and the cartesian tree.
It was a poor choice of positioning on the part of the makers, precisely because the intuitive reading makes it look like Han is “between” South Asians and Europeans.
Would you mind uploading your Fst table so that I can have a look at it directly? thanks.
deleted that plink file. and my script overwrites Fst files (same name). but i can do it again.
@razib, if you’re ever bothered to, no problem if not.
Few things using the Fst data from https://genomebiology.biomedcentral.com/articles/10.1186/s13059-017-1244-9 (“Like sugar in milk”), positioning populations using Principal Coordinates Analysis and Neighbour Joining
a) All populations: https://imgur.com/a/CqaL5
b) Pruning a) for African diversity, and Kalash and Pulliyar who form long branches indicative of drift: https://imgur.com/a/bNE1d
c) Pruning b) for mainland Eurasians only: https://imgur.com/a/aZF9S
d) Pruning c) for South Asia cline (no East Asian admix) and West Eurasians only: https://imgur.com/a/FitOZ
The Fst seems to show some decent sized offsets in the ratio of relatedness to Middle Eastern vs European populations, comparing populations that look similarly placed on the general West Eurasian->Paniya vector.
E.g. comparing their Rajasthan sample to Brahmins_UP (Rajasthan relatively more Iran, Syria, Palestine; Brahmins relatively more European), or TN_Low_Caste to Gujaratis or UP_Low_Caste (TN more Iran, Syria, Palestine; UP / Gujarat more European). Closeness to the Makrani and Brahui samples that putatively have enriched Iran_N related ancestry also seems to mirror this pattern between their samples (e.g. Rajasthan relatively closer to Makrani/Brahui compared to Brahmin, TN_LC relatively closer to Makrani/Brahui compared to Gujarat samples). That said, didn’t show up much in that paper’s ADMIXTURE results though.
Have I got these abbreviations right? ANI=Ancestral North Indian; SI=South Indian; UP=Uttar Pradesh; SC=Scheduled Caste
Hi Razib,
Would it be possible to describe how populations like CHG, Iran neolithic etc. relate to the ANI component in South Asians?
Thanks in advance if possible