
|
Sunday, September 30, 2007
"Good mathematicians see analogies. Great mathematicians see analogies between analogies."
--Stefan Banach A recent Cognitive Daily post called "Why aren't more women in science" (part 1) reviews some of the lit on sex differences in cognitive abilities. Dave Munger notes: In the verbal portion of the [SAT] test, the male advantage is eliminated if the analogy portion of the test is eliminated; arguably this is more a test of mapping relationships than literacy. The analogy portion was, of course, scrapped as of the spring 2005 SAT. [1] The boldfaced clause above shows why it matters more than the other Verbal portions: figuring out relationships between ideas matters, and reporting what some author said does not. Analogies are highly g-loaded, reading comprehension much less so. But aside from better detecting who the smarties are, analogies are more reflective of real-world math, science, and engineering. (And they matter in the humanities too [2].) If A got one more math question than B, but B got three more analogy questions than A, I'd bet on B doing better in math, even if an IQ test showed they had the same IQ. What follows is mostly a diversion to show the importance of analogies in math, starting with high school material and moving to some college material. I hope you learn something new, but mostly the goal is to put it on the record, with examples, how important a person's verbal analogy score is in predicting their success in math and science. Example 1. A bouncy-ball is dropped from 2 feet, and after hitting the ground, bounces up only 1/2 as high as its previous maximum height. Pretend that it bounces forever like this. In the long run, how much distance does the ball travel? We can make a table that shows how much distance the ball travels in a particular trip, either up or down, like so: Trip 1, 2, 3, 4, 5, 6, 7, ... Dist. 2, 1, 1, 1/2, 1/2, 1/4, 1/4, ... This problem is introduced in a pre-calculus class during the unit on the sum of an infinite geometric series -- infinite because it starts but never ends, and "geometric" meaning you multiply by the same number to get from one term to the next. The formula for such a sum is t1 / (1 - r), where t1 is the first term, and r is the constant that multiplies one term to get to the next. So if we only had these values, we'd be all set! Unfortunately, if we guess that r is 1/2, when we try to go from 1 to 1 -- we don't multiply by 1/2 anymore (or from 1/2 to 1/2). Damn. Plainly, the above series is not geometric, and at that point most students will opt to make better use of their time by yakking with friends on their cell phone. Ah, but the students in the class who are good analogical thinkers will notice a geometric series hiding behind the series above -- in fact, they'll discover two of them. The terms of one are interlocking with the terms of the other, like two rows of teeth that complete a zipper. That analogy suggests a strategy: unzip the above series. Then we have two series that go: 2, 1, 1/2, 1/4, ... and 1, 1/2, 1/4, ... Bingo! In each of these, you multiply by a constant (1/2) to get from one term to the next. And we know the first term of each, so we can plug in values for t1 and r in the sum formula. We get 2 / (1 - 1/2) = 4, and 1 / (1 - 1/2) = 2. So all together, the ball traveled 6 feet. That's a neat analogy, but it only makes sense when there are two series meshed into one. We'd like to generalize to any number of series that dovetail into one -- and no one makes zippers with more than two rows of teeth. So a better analogy might be the following:  Here there are two strands woven one around the other infinitely, with beads bearing numbers that face us, and there is a knot at the start where the strands fuse. Could we think up series with three or more geometric series hiding inside them? Sure, just as we could make a rope with three or more strands. And to make that series easy to solve, we would just unbraid the strands and work with the beads of each one separately. See note [3] for more uses of this braid analogy. Example 2. Here are some (x,y) pairs associated with a function. What is the degree of this function? That is, does it look like x, x^2, x^3, etc.? x = 1, 2, 3, 4, 5, 6... y = 2, 14, 34, 62, 98, 142... This problem also comes from high school math -- or middle school, if you took algebra then. There, you were taught to look for the difference between consecutive terms, and maybe repeat this process, until you got a sequence of the same number. The number of runs you have to make is the degree of the function. So for the above, the differences are: 12, 20, 28, 36, 44 OK, not the same number, but take the difference again: 8, 8, 8, 8 Ta-da. We had to go through 2 runs, so it must be some function like x^2 (in fact, it is 4x^2 - 2). I guarantee you never knew why this worked when you learned it -- and even after calculus or more advanced math, you may still have treated it as a mysterious trick. But there are analogies between discrete and continuous areas of math, and they are pervasive. If you took at least a semester of calculus, you know that if you take the 1st derivative of a function like 4x^2 - 2, you get something with the independent variable still in it -- 8x. And sure enough, in our discrete case, the first differences are 8x plus a constant 4. But if you then take the derivative of the derivative, you get a constant -- 8, the same 8 that appeared in our constant sequence after the 2nd run. A constant second difference in the discrete case is analogous to a constant second derivative in the continuous case. That also shows why you knew, back in high school, that you didn't have a polynomial function like x or x^2 or x^3 when you saw something like this: x = 1, 2, 3, 4, 5, 6... y = 2, 4, 8, 16, 32, 64... You can take differences of differences of differences of... and you'll never get a constnant sequence for this function, which is 2^x. In first-semester calculus, you learned that e^x is its own derivative, so that if you keep taking the derivative over and over, you always get back e^x -- the independent variable never goes away, so you never get a constant. This resilience to your effort to tease a constant derivative out of it is true of all exponential functions, which by analogy tells us that we'd never come up with a constant difference in the discrete case above. Since there are a billion other discrete-continuous analogies, I'll leave it there. I don't think they're that neat since it's only like switching between a British and American accent, not like translating between Farsi and Chinese. On a closing note, the entire domain of represenation theory in algebra is based on finding good analogies: they attempt to better understand how some group works by casting the problem in terms of matrices and linear algebra, which are better understood. All of this shows how indispensable this way of thinking is to fields that many assume are primarily about visuospatial skills (though those are key too). Analogies are to all types of thinkers what SONAR and nets are to deep-sea fishermen regardless of which species they hunt. [1] According to CollegeBoard's 2007 national report of college-bound seniors, it does appear that within the past couple of years, the male mean for Verbal is only about two points above the female mean, shrinking from a difference of about 11 to 12 points that had persisted since about 1980. And at the high end, in 2007, 1.98 % of males and 1.84 % of females scored 750 - 800. Data from other years on the elite scorers are not contained in the 2007 report, and I'm not interested enough in this topic to pursue them. The point is that gutting the analogy portion seems to have served its purpose. [2] When the retiring of the analogy questions was announced, an educator named Ted Sutton got an op-ed into the very liberal Boston Globe and made a guest appearance on the very liberal radio show On Point (which airs on NPR). He lamented the change, focusing on the centrality of analogies to the great philosophical and humanistic traditions. Older-style liberals like Sutton appear unaware that their social engineering cousins are the ones responsible for flushing great ideas down the drain, so that the gap between the sexes on a test might close. At least there are still analogies on the GRE -- despite a plan to re-vamp the test with the same gap-narrowing agenda in mind. And thank God for the Miller Analogies Test -- not a single "how does the author most likely feel about X" question at all! [3] The braid idea can also guide your intuition when you have a homework problem in a college-level course that says: "Prove that a countable union of countable sets is countable." I provided a visual proof here (with a more detailed proof at the end), but I didn't think of the braid analogy, which makes it even easier to picture. The argument is as I wrote before, but when you're introducing yet another countable set into the union, it's like adding a new strand to a rope. You look at the place where the n strands have shown themselves once -- and before the first strand winds around the second time, you push it over and braid in your new strand. When they n strands have shown up twice, you push the first strand over before it winds around the third time, and there's the second place where the new strand goes. And so on to infinity. The union of these strands is a rope whose beads are countable and, more importantly, ordered in a straightforward way. More explicitly, we can think of the strands as equivalence classes and the rope as the space they fill out. We can imagine a rope that extends infinitely in either direction, like the even and odd integers woven together. We've already seen a rope with a knot but which continues to weave itself forever in one direction. A rope with knots at both ends is pretty boring -- unless they were the same point, i.e. the rope circled back so that each strand fed back into itself, as with a sequence that's cyclic (for instance: x, y, x^2, y^2, x^3, y^3, x, y, ...). Labels: general intelligence, mathematics 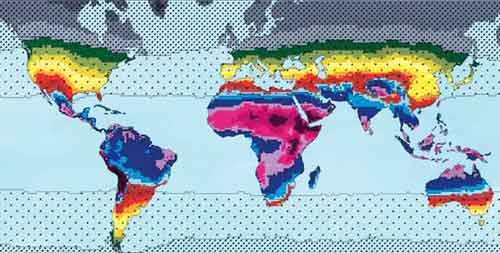 Update: I've added some geographic and ethnic notations to the ones that are relevant. For example, the Indian groups which are the darkest for their latitude turn out to be a Dalit and Tribal sample. In contrast, the other groups are more socially diverse. In South Afica the Capetown sample consists of mixed-race Coloureds. I've also added geographic data for places like Ireland, since I know there are readers who might be able to confirm with local knowledge (or disconfirm). Update: I've added some geographic and ethnic notations to the ones that are relevant. For example, the Indian groups which are the darkest for their latitude turn out to be a Dalit and Tribal sample. In contrast, the other groups are more socially diverse. In South Afica the Capetown sample consists of mixed-race Coloureds. I've also added geographic data for places like Ireland, since I know there are readers who might be able to confirm with local knowledge (or disconfirm).End Update From The Evolution of Skin Coloration by Nina G. Jablonski Figure 1: "The potential for synthesis of previtamin D3 in lightly pigmented human skin computed from annual average UVMED. The highest annual values for UVMED are shown in light violet, with incrementally lower values in dark violet, then in light to dark shades of blue, orange, green and gray...In the tropics, the zone of adequate UV radiation throughout the year (Zone 1) is delimited by bold black lines. Light stippling indicates Zone 2, in which there is not sufficient UV radiation during at least one month of the year to produce previtamin D3 in human skin. Zone 3, in which there is not sufficient UV radiation for previtamin D3 synthesis on average for the whole year, is indicated by heavy stippling." Below the fold I've reproduced a table that compares expected skin color and observed skin color for indigenous people. The expected is derived from a prediction equation which uses the observed values and combines them with the values from the UV map above: Predicted skin color = (annual average UVMED) X (-0.1088) + 72.7483 I also added a column which measures the difference between expected and observed and ordered it from populations which were lighter than expected to those which were darker than expected. Many of the values seem explicable via historical information (go to the paper and in the appendix you see what populations they used, that's important information); nevertheless, I am wondering about possibilities of different diet and its affect on skin color (more later)....
Notes: I'm skeptical of the accuracy of some of the reflectance measures. The authors report which ethnic groups they used for sampling in the appendices, so I would ask readers to look in there if they think some of these measures are questionable (I'll have a follow up post on this). They also assume that these "indigenous" peoples (which is, admittedly, a flexible definition) are well adapted to their local UV regime, and that other factors are controlled. Jablonski's thesis is that skin color is driven by two opposing forces: adaptation to high levels of UV which break down folate and increase birth defects, and, the need to synthesize vitamin D through the interaction of UV and biochemicals in the skin. Variation in diet and other possible selective forces aren't of much concern to her, and so she generated her expected skin color values assume that UV is the primary independent variable. My own hunch is that the far lighter than expected skin color across much of Asia is due to Vitamin D deficiency induced by the extreme carbohydrate biased diets of these populations. At this point this is just a tentative hypothesis, but, there has been selection for alleles known to be implicated in generating lighter skin in both South and East Asia within the last 10,000 years. Labels: Genetics, Pigmentation
I don't know if we should believe Svante Paabo anymore, but his lab has some new findings re: Neandertal mtDNA:
Neanderthals in central Asia and Siberia Nature advance online publication 30 September 2007. doi:10.1038/nature06193 Labels: Evolution  The role of biology in constraining/enabling human culture is largely underappreciated outside of, well, the small group of people who study biology and culture. But that role is clearly enormous. Consider, for example, what is sometimes referred to as "cryptic ovulation"-- the fact that human females do not conspicuously display the fact that they are ovulating. In many other primates, the females have a patch of hairless skin that, as ovulation approaches, swells up bright red (see the picture of this in a baboon), signaling that she is fertile and driving the males a little crazy. Humans clearly do not do this, and I don't think it's an exaggeration to claim this was a biological prerequisite (or as close as you can get to one) for today's mixed-gender offices and the large-scale incorporation of women into the workforce. The role of biology in constraining/enabling human culture is largely underappreciated outside of, well, the small group of people who study biology and culture. But that role is clearly enormous. Consider, for example, what is sometimes referred to as "cryptic ovulation"-- the fact that human females do not conspicuously display the fact that they are ovulating. In many other primates, the females have a patch of hairless skin that, as ovulation approaches, swells up bright red (see the picture of this in a baboon), signaling that she is fertile and driving the males a little crazy. Humans clearly do not do this, and I don't think it's an exaggeration to claim this was a biological prerequisite (or as close as you can get to one) for today's mixed-gender offices and the large-scale incorporation of women into the workforce. But how cryptic is the human cryptic ovulation? Women are generally aware of where they are in their cycle, and men with long-term girlfriends/wives have probably noted subtle physiological changes (in breast size, for example) that correspond to their partner's hormonal fluctuations. Is this a subtler version of the sexual swelling in other primates? There is some evidence that this is the case, but Geoff Miller and colleagues take a rather novel approach to the question: 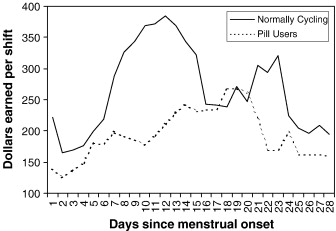 To see whether estrus was really "lost" during human evolution (as researchers often claim), we examined ovulatory cycle effects on tip earnings by professional lap dancers working in gentlemen's clubs. Eighteen dancers recorded their menstrual periods, work shifts, and tip earnings for 60 days on a study web siteThis is a nice way at getting around subjective measures of "attractiveness" in studies like this-- the amount of money made by a stripper probably corresponds pretty well to how physically attractive the males in the audience find her. And as seen in the graph on the right, there's a noticeable peak in earnings among normally-cycling women at around 10 days (ovulation). The sample size is small, of course, but the effect is consistent with other evidence than human females modulate their physical appearance and behavior according to the menstrual cycle, so I'm inclined to believe it. And needless to say, if this is the case, it suggests a rather simple profit-maximizing strategy for the professional lap dancer. Labels: Evolutionary Psychology
Anyone trying to understand heritability, or other aspects of quantitative genetics, is likely to rely heavily on D. S. Falconer's Introduction to Quantitative Genetics. I find that Falconer died a few years ago, and there is a fine Obituary by W. G. Hill available here. I love this anecdote from Falconer about D'Arcy Thompson:
I asked him at the beginning for recommendations as to what to read and he said 'Just browse, my boy, just browse.' So I worked away on my own ... and at the end of the year he came along to me and said 'Well, Douglas, my boy, you're a very good lad and I don't think we need give you an examination this year.' They don't make them like that any more.
Saturday, September 29, 2007
There has long been a tiresome debate in evolutionary biology (or at least in pop science books about evolutionary biology) whether evolution generally proceeds gradually or in bursts alternating with stasis. But I wonder: what about cultural evolution? With evolutionary biology we can look at fossils and the molecular substrate to determine the nature of change; with culture it is a little different because of its amorphous character. Some aspects are pretty easy to quantify, for example baby names for example drift like genes subject to purely random forces. On the other hand, my perception is that attitudes toward homosexuality have changed very fast over the last 15 years, so that some of the positions staked out by "social conservatives" in 2007 would be out of the mainstream for being too pro-gay in the late 1980s (here are polls). Has anyone out there plotted changes of attitudes from sources like Gallup and noticed whether the changes were gradual or subject to sharp increases or decreased in frequency?
Labels: culture
The Lancet has the case report.
Friday, September 28, 2007
What is contingent across the arc of human cultural development? What is inevitable? Interesting, if difficult to answer, questions. Last year I posted No fear of Patrick Henry College - the Borg shall assimilate. My argument was simple: an explicitly Christian institution which attempts to take over "secular" culture will be assimilated. There are long, and tiresome, historical debates about whether this in fact happened to the Christian churches when the Roman state adopted them and turned them into the Universal Church. But more recently, and specifically in the context of universities, there has been a long track record in the United States of Christian institutions being founded to stem the tide, only themselves to be swallowed up by the rising waters.
Harvard was originally a training ground for Calvinist ministers. Over its first century it became progressively more heterodox. Princeton was founded explicitly to serve as a second Harvard, a bastion of Calvinist orthodoxy. It too was suborned. Wheaton college is in many ways the Harvard of contemporary evangelical America; and it reaffirmed its Protestant credentials when it fired a professor who converted to Catholicism. Nevertheless, the act itself was not without controversy on the campus, suggesting that the commitment toward ideological purity has wavered. Additionally, it seems clear to me that Wheaton's loyalty to one American subculture has resulted in constraining its influence. Patrick Henry College reached out, its aim was to conquer the public space. But last spring while I was busy at something I like to call "life" a shakeup occurred at Patrick Henry, half a dozen faculty members left (there are fewer than two dozen told faculty members). Why? Ideological conformity and theological purity were being compromised. Patrick Henry aimed for the stars, recruited bright students and challenged the faculty. But such an environment naturally leads to intellectual hubris and the pushing of boundaries. Mental meekness and dullness often go together. Like an invasive species unleashed to control a pest any attempt to conquer the mainstream by mastering its toolkit may inevitably be self-defeating. This is not just true of the evangelical Christian subculture. Books like Bobos in Paradise document the paradoxical stances of the bohemian bourgeois; 60s radicals turned "socially conscious" entrepreneurs & mercenary professionals. American culture is a massive and uncontrollable river. On occasion it changes course or jumps its bed, but it has its own will and logic and can process anything thrown into its maw. The extruded cultural material is often totally transformed, but the the human tendency to self-delude is great enough that those who have been reprogrammed by the river truly believe that they have won. There's no point in standing athwart history if it will only drown you; 'tis far more productive to make use of the power of the current and outfit your ship appropriately so that your journey is as smooth and pleasant as possible. Related: The New York Times has an interesting article about a new Christian college, New St. Andrews. I obviously don't share their presuppositions, but I do respect their passion for learning. As long as books & faith are their focus they will persevere on their island surrounded by the river. If they challenge it then I suspect their fate is predestined. Labels: Religion
Thursday, September 27, 2007
I don't follow the non-science news very closely. I'm curious about what's going on in Myanmar/Burma, if you have an interesting link, drop it in the comment box. Thanks.
Labels: politics
Cosma Shalizi has put up a gigantic post on IQ & heritability; he originally titled it "Duet for Leo and Razib," implying that I, and the audience here @ Gene Expression, are the targets of his eloquence (at least in part). Now, I have to admit something, I'm not really interested in psychometrics that much anymore. It has been a while since I have been, stupid people are obviously stupid and I am not interesting in debating that fact. I take my own opinions in this area as background assumptions, so I'm not going to respond to Cosma. In fact, I won't read the post right now, there's some interesting stuff on HLA & heterozygosity that I want to check out! But, I do invite readers to digest what Cosma is saying, because I guarantee you that you'll see it replicated by lesser minds elsewhere.
Labels: human biodiversity, IQ
Sadly, but unsurprisingly, the little blonde girl photographed in Morocco turns out not to be missing British girl Madeleine McCann, but the daughter of a Berber farming family, who are said to have three other blonde children.
Most of us will have been vaguely aware that blonde hair and fair skin are not uncommon among the Berbers, but it has evidently come as a surprise to the general public. It is usually explained by a hypothetical element of European ancestry, whether from Roman slaves (as in this Daily Mail article), the Vandals, or more prosaically from the colonial occupation by French soldiers and government officials (who presumably didn't just twiddle their thumbs). I wonder if there is any hard genetic evidence? Y chromosomes might at least show whether the paternal ancestry is recently European. An alternative, and more interesting, explanation would be that the Berbers are the remnants of an older, more 'Caucasian', North African population. Labels: Pigmentation
Wednesday, September 26, 2007
Native Americans get custom sneaker:
Nike researchers and developers spent two years designing the shoe, traveling to seven locations to look at the feet of 224 Native Americans from 70 different tribes. They created a shoe to fit the average Native American foot, which is wider than the foot the Nike Air Pegasus running shoe is designed to fit. About 164 members of the Confederated Tribes of Warm Springs tested prototypes of the shoe before its release, the company said. This is fascinating. The reason these shoes were developed was to encourage physical activity, something that comes more naturally when your feet aren't aching. Assman has noted before that South Asians might be more flexible than the typical human, which likely results in flatter feet, so this foot's-eye viewpoint might be pretty practical in tailoring shoes toward populations. Labels: human biodiversity
RPM's slamming of some silly coverage of the C-value enigma got me thinking about the problem of why we see the sorts of variation we do in the amount of non-coding DNA between species. People are right to heckle the questionable assumption that these differences in ncDNA have anything to do with the evolution of phenotypic complexity (though probably a small fraction do), but I think it might still have an interesting functional tale to tell. I'm probably not the first to think of this, but the idea is that variations in quantity of ncDNA are not functional for the organism in themselves but rather the waste product of a particular kind of functional change: gene duplication.
Recall that eukaryotic genomes are regularly bedevilled by selfish tranposons. These are rogue genetic elements with a vested interest in creating duplication events, and the basic idea is that every once in a while one of them will succeed wildly at it and in the process end up dragging a whole gene along for the ride (maybe several times). Most of the time this will be bad, but occasionally it'll be good, and sometimes it'll be nearly-neutral and you'll see functional divergence on the copied locus after the initial duplication event. In the cases where a duplicated gene confers a selective benefit, the newly formed transpositional elements hitchhike along on the newly selected gene's coattails. The upshot of this is that we should expect cases of adaptive evolution via gene duplication to be frequently be accompanied by increases in the amount of transpositional cruft in the genome of the species. This also would neatly account for much of the ncDNA variation between species, since gene duplication seems to play an important role in the emergence of species-specific traits. If this idea is correct, the amount of ncDNA should correlate more highly with how much adaptive gene duplication a lineage has undergone rather than phenotypic complexity per se. This theory should be pretty easy to test: Look at cases of adaptive gene duplication that have happened relatively recently (geologically speaking) and compare the LINEs and such around these loci with those close to the presumed "parent" locus. The further back in time you go the harder it will be to do this comparison due to drift wiping out the traces, but in the cases that are comparable they should have a very similar pattern of nonfunctional repeats. If I have this right. (EDIT: Duh. This isn't a good test, since you'd probably see the same thing under any sort of duplication. Need to think of something else. Maybe compare lineages of recently duplicated genes: If gene B is a "recent" duplication of gene A, and gene Y is a "recent" duplication of gene X, but genes A and X diverged an extremely long time ago, then the two duplications were probably caused by different retrotransposons and so the LINEs around A and B should tend to be highly similar to each other but very different than those around X and Y, and vice-versa. You'd probably have to compare a bunch of different gene lineages to get a statistically significant result, though, and I don't know how easy it would be to find enough good candidates.) Has anyone actually looked at anything like this? Does this idea hang together? How else could we test it? Update: Looks like another beautiful hypotheses slain by an ugly fact. I'll just copy-paste what I said in the comments: Having looked into it, this doesn't work the way I thought it would. I knew that LINEs sometimes end up dragging some of the host's genetic material along in their replications, but now I know that the way this happens is that sometimes the reverse-transcription machinery grabs onto host mRNA that's floating around and splices it in. So what's being inserted is automatically a pseudogene since the mRNA has already been processed (i.e. there's no promoter attached to it). For this idea to work it would need to be an active gene. Rats. Labels: non-coding dna, selfish dna, speciation
Tuesday, September 25, 2007
In my post below I respond to Bryan Caplan's critique of Greg Clark's claim that disease can increase per capita income because it reduces population (i.e., same population has a bigger resource base to work with).1 I go the route of the two handed economist by suggesting that whether Clark or Caplan is right depends on the details.2 Herrick adds in the comments:
Caplan's big claim is that almost anything that persistently raises death rates is likely to persistently reduce output per living worker. It that true? As I suggest below I think that Caplan is wrong if he wants to claim that productivity is always decreased in direct proportion to the increased disease load (ergo, death rate) of a population. This would prevent the rise in incomes which Clark predicts as the lower productivity of each individual means that the same amount of land can support fewer people at or above subsistence. In A Farewell to Alms Clark reports a rise in incomes after the Black Death, and, amongst native peoples in the New World after Old World diseases ravaged them. Obviously this is one extreme cause: a highly lethal infectious disease which cuts down a large proportion of the population very quickly, and then recedes. The other scenario is a case where there is an endemic infection which reduces physiological fitness across the whole population, reducing lifespan and increasing death rates, but also dampening economic productivity. Then there are cases where there is a wide variance within the population in regards to susceptibility toward infectious agents. This might be more like the first scenario, a large number of people die very quickly, while many others are spared because of some immunity. And so on. From Darwinian first principles it seems that there should be a large number of pathogens which are infectious but not fatal. Though reducing physiological fitness, they don't knock out their host because to do so would result in their own reduced evolutionary fitness. But hey, Herrick asked for expert opinion. I was actually hoping that someone with medical expertise (e.g., tropical diseases?) would weigh in on that thread, but that didn't happen. So I come to you with open hands and ask you to enlighten.... Update: Greg Clark responds directly to the Caplan critique. As a non-economist I'm more interested in what the empirical historical data says, and what little I know seems to agree with the general thrust of Clark's point. 1 - That sentence should filter out chimpanzee readers since it should be totally incomprehensible to them. 2 - No shit it depends on the details! Labels: Medicine
Apropos of a previous post on race, PLoS Medicine has just published two (opinion) articles on the use of racial categories in medicine. There's only a cursory treatment of genetics (and the treatment that's there is pretty bad), but it's sometimes useful to see another take on the issue. The message I get is that, well, doctors aren't trained in genetics, so any "race-based" medicine (which is necessarily based on probabilites) is likely to become a sort of "black = medicine X, white = medicine Y" dogma.
A note for readers, there's a new book aimed at the popular audience, Justinian's Flea: Plague, Empire, and the Birth of Europe. You can find reviews here and here. I'm going to pass on it probably because it is a general interest book which doesn't introduce any original material, but it looks like some readers of this weblog get something out of it (though do read Plagues and Peoples if this genre is new to you).
Labels: History
I'm not going to spend too much time on this, but Larry Moran has responded to my post. He, of course, makes it sound as if he's being perfectly reasonable. But consider what he wrote in July:
[E]volutionary biologists like Dawkins and the other adaptationists should have known about random genetic drift. Isn't it amazing that they don't?And compare with his new line: There are many adaptationists who recognize that random genetic drift exists. They will, when pressed, admit that neutral alleles can be fixed in a population.He goes on to dispute that his quotation from Dawkins was misleading. I obviously disagree, because I was misled! When Dawkins writes "If a whole-organism biologist sees a genetically determined difference among phenotypes, he already knows he cannot be dealing with neutrality in the sense of the modern controversy among biochemical geneticists", I assumed (as most readers likely did) that Dawkins was dogmatically asserting that absolutely no phenotypic change can be neutral. He wasn't, of course. In any case, if Moran wants to define an "adaptationist" as someone who hypothesizes an adaptative force driving most phenotypic changes, then sure, Dawkins is probably an adaptationist, as am I and many reasonable biologists. Hypotheses have to be confirmed, of course, and "adaptationism" (tempered with knowledge of demographic forces) is a powerful hypothesis-generating machine. Keep in mind that one of Moran's "textbook examples" of neutral phenotypes is eye color. OCA2 (the major locus controlling eye color in humans) of course shows one of the strongest signals for selection in the human genome. I have hypotheses about why this is (could be an example of pleiotropy), but if you can just assert that eye color is a neutral character, why even bother? UPDATE: Larry Moran claims the first of his quotes above was both ironic and sarcastic. Judge for yourself (in his favor, the claim is obviously wrong. in his disfavor, if you weren't familiar with Dawkins's writing, it wouldn't seem obviously wrong). Maybe he means ironic in the Canadian sense.
Monday, September 24, 2007
Bryan Caplan has initiated a series of posts where he will critique some aspects of Greg Clark's book A Farewell to Alms. Caplan starts by disputing Clark's implication that the Four Horsemen can increase per capita income simply by reducing population. I would say he makes some good points, but he does leave an opening:
...A plague might do the trick - it kills some outright, and weakens the rest. In the long-run, the survivors will have a higher material level of living. But this hardly makes the plague a "friend of mankind." All it means is that after mass death, the frail, disfigured survivors will get to eat some extra calories beside the graves of their families. With friends like this, mankind doesn't need enemies. The after effects of disease vary quite a bit from pathogen to pathogen and person to person. Additionally, to some extent plague might be a partly exogenous variable, on occasion cutting through populations like a scythe for a few short years and then abating mysteriously for decades. I think this is why the conditions after the Black Death are a good case study which probably leans toward Clark's contention. 25% of Europe's population disappeared, but the survivors were not 25% less healthy or productive. In any case, add Econlog to your RSS to keep track of the debate. Update: Arnold Kling is feeling Clark more than Caplan. Labels: Economics
A comment below asked about a notation in a particular passage in a book I referenced. As it turns out the book is fully searchable on Amazon. Myself, I do searches on google books, and if there isn't a "view" of the book I'm looking for (or that page isn't viewable), I will check for the book on Amazon. This covers a large proportion of the "fact checking" one might need to do. Also, google scholar is pretty well integrated with books, so you might just want to start out there. Here are the libraries who have signed on to google books, so you can imagine that the coverage is pretty good.
Labels: Blog
I am now reading the translations of the basic writings of the Confucian Sage Xun Zi in my spare time. Like much of body of Chinese work on moral and political philosophy from this era the prose is allusive and often meanders from obscure analogy to opaque metaphor. But the passages from the chapter titled 'A Discussion of Heaven' are clear as day. An illustrative example:
You pray for rain and it rains. Why? For no particular reason, I say. It is just as though you had not prayed for rain and it rained anyway. The sun and moon undergo an eclipse and you try to save them; a drought occurs and you pray for rain; you consult the arts of divination before a decision on some important matter. But it is not as though you could hope to accomplish anything by such ceremonies. They are done merely for ornaments. Hence the gentleman regards them as ornaments, but the common people regard them as supernatural. He who considers them ornaments is fortunate; he who considers them supernatural is unfortunate. Those familiar with Xun Zi would not be surprised by these sorts of comments. Of the early Confucians he was arguably the most rationally oriented as well as being thoroughly grounded in the empirical reality of the world. That should not be surprising since his life overlapped with the tumultuous period before the unification of China by the First Emperor. The nostalgia for the past and preoccupation with ancient exemplars which is a hallmark of Confucius' thought is understandable insofar as the halcyon Golden Age of the Zhou had only just passed. In contrast by Xun Zi's day such memories were very distant indeed, emulation of the past had to give some ground to compromise with the needs of the present so that one could live in the future where one could strive toward proper conduct. That being said, I do think that Xun Zi's comments should help us put into perspective the conceit that we moderns have that all ideas which gush from our minds are new to the world. In The Blind Watchmaker Richard Dawkins' famously asserted that only with the emergence of Charles Darwin's theory of evolutionary change via natural selection could one be an intellectually fulfilled atheist. In an act of historical psychoanalysis Dawkins offers that he believes that David Hume, who rejected God not because there was another explanation but simply because he did not find it be be any explanation at all, would have agreed with his assessment at the end of the day. Xun Zi expresses very Humean attitudes 2,000 years before Hume, and like the great Scottish philosopher he is content to observe that Heaven simply is. Instead of plumbing the ontological depths of the universe Xun Zi was rather more interested in the maintenance of a robust and stable social order which he noted was on the edge of collapse all around him. Faced with stress and uncertainty Xun Zi did not turn to the gods for salvation (and quite clearly he was skeptical of their very existence as personal entities), nor did he collapse in godless nihilism and give himself up to a life of Epicurean pleasure. In The Geography of Thought the author argues that one major chasm which separates the Eastern and Western cognitive styles is that the former is less systematic, more open toward contradiction in the service of a pragmatic short term solution to a problem. In contrast, Westerners, exemplified by the Greeks, reveled in their exploration of the nooks and crannies of cognitive paradoxes as the sine qua non of the highest levels of reflective philosophy. Xun Zi's shallow naturalism, his punting of the mysteries of the origin of life and its ravishing diversity, may not be intellectual satisfying if the essence of thought is to assemble nature together at all its joints in a vast seamless arc, but it is a very conventional and common attitude among a wide range of people. In India the Carvaka movement promoted a materialistic philosophy which resembled Epicureanism. In the Greek world Epicureanism, Skepticism and Cynicism were all schools which exhibited naturalistic streaks. Their attempts, if made, to provide a grounding for the existence and dynamism of the world around us are rather laughable, though perhaps less so in an intellectual climate where some might have taken Hesiod's cosmogony seriously (see clarification). The purported systematic and idealistic bent of the Greeks when it came to the rationalization of atheism seems to be so much window dressing. At the end of the day it seems that they simply didn't believe, the gods were ludicrous, and if that was good enough for Hume and Xun Zi, it was good enough for them. It may be that there are two sets of atheists in the world. One set of atheists is historically contingent and one set is not. The former may find Darwinian evolution, which draws in part from Paley's Argument for Design, a satisfying narrative for their thirst for why. Prior to Darwin these atheists might have had to quench their thirst for the why with some form of theism, not for them the dispassionate ignorance of Hume, they require some gnosis. The second set of atheists are ahistorical, not only do they not thirst overwhelmingly for the ultimate why, but their intuition as to the naturalistic nature of the universe mitigates any unease that their agnosticism might foster.1 This is where Xun Zi exhibits a lack of systematic thinking, he plainly asserts that there must be a cause for every effect, a point which to a typical teleological human would imply a world filled with bubbling godlings. But no, for Xun Zi there is only impersonal and unfathomable Heaven to which notables may make fictional sacrifices to maintain public order and satisfy the need for rites. In The Blind Watchmaker Richard Dawkins comes close to giving his fellow countryman Charles Darwin credit for inventing the idea which slew God, as if atheism hinged upon the British imagination. These perceptions are confirmed in works such as God's Funeral: The Decline of Faith in Western Civilization, which narrates the shift toward agnosticism on the part of British intellectuals in the 19th century concomitant with the rise of Darwinian theory, prefigured by the ideas of Hume and Edward Gibbon. But Xun Zi shows the Humean strain in Chinese thinking which existed long before the birth of Christ, an intellectual tradition which persisted across the centuries down to the early modern era and sparked Sinophilia on the part of free thinkers such as Voltaire. In A Farewell to Alms the economic historian Gregory Clark describes the massive gains in income to the masses over the last 200 years and the radical equalization of the social order. The middle class American consumer has nothing in common in their daily life with the marginally alive Chinese peasant of Xun Zi's day. On the other hand, the ruminations of the typical literary intellectual, the pundit caste given space on our op-ed pages, might be no better than the reflections of the ancient Chinese political philosophers, who played being both humanists and social scientists. While the great lift off in natural sciences has occurred only in the past few hundred years, perhaps the vast majority of the genuine original value from the humanities and philosophy was generated within the first few hundred years of the Iron Age? 1 - To be clear, these two sets of humans are atypical and narrow slices to begin with. Most people, I believe, do not need genuine explicit gnosis, rather they simply believe in an unreflective manner. In many ways the second set of atheists, who naturally have little intuitive belief in a supernatural order or a need for an ontological buoy in the universe, may have more in common with the typical human in their unreflectiveness. Where they differ is that their basal intuition is atypical; most humans intuitively grasp the likelihood of a supernatural order while some atheists do not.In contrast, a small minority of humans have deep and passionate fixations on the why questions. I would argue these are the most attracted toward philosophies which purport to explain it all via theology, scientism or mysticism. Their souls demand and account for why they exist to demand an account in the first place. Labels: History
Sunday, September 23, 2007
There are few things that irritate me more than the deliberate distortion of an argument. It's especially irritating when I end up believing said distortion. An example:
Larry Moran has been railing (as he is wont to do) against what he calls "adaptationists"[1] in a couple recent posts. The "adaptationist" is a scientist who believes that every phenotypic trait is an adaptation to some selective pressure. It is clear that this view is wrong-- it's certainly plausible that phenotypes evolve neutrally, and the examples in Moran's posts are possible candidates, though there's no evidence for neutrality (other than Moran's intuition, of course). The high frequency of the O blood group in Native Americans is a better candidate--the population bottleneck as humans expanded into the Americas likely involved large stochastic changes in allele frequency. In fact, the view Moran attributes to the "adaptationist" is so obviously wrong I wondered whether perhaps we should append the word "mythical" to this creature's name. Moran responded, quoting this passage from Richard Dawkins's The Extended Phenotype: The biochemical controversy over neutralism is concerned with the interesting and important question of whether all gene substitutions have phenotypic effects. The adaptationism controversy is quite different. It is concerned with whether, given that we are dealing with a phenotypic effect big enough to see and ask questions about, we should assume that it is the product of natural selection. The biochemist's 'neutral mutations' are more than neutral. As far as those of us who look at gross morphology, physiology and behaviour are concerned, they are not mutations at all. It was in this spirit that Maynard Smith (1976b) wrote: "I interpret 'rate of evolution' as a rate of adaptive change. In this sense, the substitution of a neutral allele would not constitute evolution ..." If a whole-organism biologist sees a genetically determined difference among phenotypes, he already knows he cannot be dealing with neutrality in the sense of the modern controversy among biochemical geneticists.This certainly seems to place Dawkins as an "adaptationist", one who thinks that all differences in phenotypes are adaptations. I was a little surprised by this, but the quote seemed clear, and I wasn't going to take the time to find my original. Luckily, another commenter pointed out that The Extended Phenotype is searchable at Google Books. And funny, the very next line after Moran stops quoting is possibly relevant: If a whole-organism biologist sees a genetically determined difference among phenotypes, he already knows he cannot be dealing with neutrality in the sense of the modern controversy among biochemical geneticists. He might, nevertheless, be dealing with a neutral character in the sense of an earlier controversy (Fisher & Ford 1950; Wright 1951). A genetic difference could show itself at the phenotypic level, yet still be selectively neutral.Dawkins goes on to express some skepticism about some arguments for evolution by drift, but he's certainly not an "adaptationist" in the Moran sense. I suppose I'm somewhat naive: distorting someone's argument through selective quotation is a classic creationist tactic, and Moran has written a bit about the propaganda techniques used by that crowd. Little did I know his familiarity is not of an entirely academic sort. [1] As opposed to "pluralists", as he likes to call himself. For someone who (rightfully, in my opinion) is disdainful of "framing" (the view that scientists need to spin their results in order to resonate better with the public), he certainly knows how to frame.
Dissent has published an article on how pro-choice advocates should start thinking about the prospects of designer babies and the author broaches the subject of regulating, and perhaps prohibiting, access to such procedures. What's striking about the article is the heavy reliance on the "barn door effect" wherein pro-choice advocates, once through the barn door, slam it shut in order to prevent others from using the same rationales to get through the door. For example:
Now, we who support abortion rights may fear that regulating reproductive technologies could endanger our cause. There is no doubt that maintaining the legality of abortion-and fighting to reverse harmful restrictions of it-is paramount. But it is also important for us to sustain a larger moral vision. The larger moral vision which the author seeks to protect imposes a cost of loss of reproductive freedom on couples who wish to use reproductive technologies. During the Abortion Wars the pro-choice advocates rejected the very notion of a larger moral vision being protected at the cost of individual reproductive freedom yet now, through the use of selective definition, wherein abortion is synonymous with reproductive freedom and the use of reproductive technologies falls outside the definition, some seem fine with the very idea of limiting individual choice in order to advance their vision of a societal interest. One of the lines of argument she develops begins with the premise that "individual choices can have larger social consequences." I wonder what the author's response would have been to this same premise being used in the early abortion battles, for abortions themselves also create larger social consequences. As women exercise their individual right to abortion they create effects that ripple through society. The same process is at work with regard to access to birth control. The author makes much of the arbitrary line in the sand she's drawn wherein she places high value on individual liberty for women to control their own bodies and timing of reproduction yet she devalues the individual choice of embryonic trait selection which leads me to question whether she stands for principle or outcome. If the principle of individual liberty is paramount, as we see with free speech cases where disagreeble speech is frequently defended, then we should expect support for individual exercise of reproductive freedom even when one may personally disagree with the choice made. If the outcome is of the highest importance, then we should see the jettisoning of principle when it is no longer convenient. I believe the author is arguing the latter position and this may come to be exploited by those who oppose her viewpoints on abortion, for if one jettisons principle when it is inconvenient to one's immediate concerns then it becomes harder to argue on the basis of principle when one's position is threatened. I find it interesting to watch these early stumblings on the question of reproductive technologies and the shifting alliances that may result. Earlier I took a rudimentary stab at outline the shifting alliance in the post The Turning of the Tides. One of the most glaring examples of the conundrum reproductive technologies pose for dogmatic feminists was laid bare within this post, Feminist != Support for Reproductive Rights. While the ideological contortions are interesting to watch what I find most amazing is the penchant for social engineering by fiat. The belief that legislation which restricts a couple's reproductive choice will adequately address what the author see as a problem and that people shall willingly constrain their reproductive choices. Bush and Kennedy championed a law (NCLB) which mandated that all students shall meet proficiency standards in their educations. How's that working out? Is the War on Drugs eliminating all drugs from society? Before abortion was widely legalized, did laws against abortion prevent abortions from taking place? Do Bio-Luddites really believe that prohibitions on advanced reproductive technologies will eliminate choice for parents? The most likely effect will be to drive such parents to underground providers or to exercise their choice overseas, in countries like China, where attitudes on this topic are quite different: A survey of Chinese scientists working in the field of genetics suggests they overwhelmingly support eugenics to improve public health. If the authors worried about a class divide developing between the "GenRich" and the rest of the population then the surest way to bring this about is to create a regulatory framework where only those with means can access the service by traveling overseas in order to have their embryos transfered. Does the author imagine that US Customs will maintain a pregnancy screening service for Americans arriving back in the country, or that abortions will be forced on people who have been found to have used reproductive technologies, or that the children, once born, will be born with a Scarlett Letter emblazoned on their foreheads announcing to the world that they are "GenRich." Labels: civilization, Genetic Engineering
The other day, I mentioned a silly article in Nature Review Genetics complaining about the state of science journalism. The author seems to think that journalists are promoting "genetic determinism", so let's consider her evidence. The study she cites asked focus groups, "What does 'a gene for heart disease' mean?", and coded their answers as "No risk", "Absolutely determined", or "Heightened risk".
Now, before I tell you the results, here's Condit's interpretation of them: "Most people interpret statements of genetic causation in a highly deterministic fashion...Avoiding deterministic implications is consequently challenging." So most people must have fallen into the "absolutely determined" category, right? Here are the results: No risk: 15% Absolutely determined: 28% Heightened risk: 56% So the majority of the individuals got it right! In a world where 1 in 5 Americans believes the sun revolves around the Earth, that is absolutely astonishing, and perhaps a sign that the public is getting the message about genetics on its own. Of course, if that were the case, there would be no need for scientific communications experts like Dr. Condit... Labels: Genetics
Tim Krueger writing in the Cornell Daily Sun focuses on the higher admissions hurdles that Asian applicants to Cornell face and advocates that something be done about this injustice. By his back of the envelope calculations:
In the interest of space I'll put the calculations on The Sun website instead of here. The figure I arrive at suggests that Cornell would have around 258 more domestic Asian/Pacific Islander undergrads in the absence of racial considerations in our admissions process. He began his editorial with some promise by making note of the distorting effect of racial preferences, but he just couldn't commit to the consequences of a merit system and falls back on tinkering with racial gerrymandering but unlike most of the advocates of Affirmative Action, with their stale, run of the mill, pronouncements, Mr. Krueger offers us a grand vision: Noting that Cornell is a truly global institution, can the geographic limits of its responsibility to educate defensibly be established within the U.S.? I would argue not. And if Cornell has a global responsibility, any affirmative action policy rooted in this second "instrumental" argument would be expected to aim for a student body that's a microcosm of global, not simply U.S., demographics. So let's cut to the chase, what does he propose be done about the plight of Asians not being admitted on merit? Implement a merit-based admissions system? Nope: Does this mean Cornell should end racial considerations in admissions? Of course not - the rest of Berkeley's demographic story boasts a black population of only 3.8 percent. . . . . Either of the above constructions of affirmative action justifies its application towards blacks, Latinos and Native Americans. The loosening of admissions standards for Asians should instead come at the expense of white applicants. This would strengthen the academic caliber of our student body while furthering our commitment to diversity; the combination should not be taken lightly. I eagerly await news of Mr. Krueger's withdrawal from Cornell in order to make room for the meritorious Asian or the Diversity-embodying Black, Hispanic or Native American. Come on Mr. Krueger, do your part.
Saturday, September 22, 2007
This week's Science has a news article detailing the strides being made in dog genetics since the publication of the dog genome. Dogs should be one of the best model organisms for studying the genetics of behavior-- artificial selection on behavioral traits over the centuries should allow the relevant genes to be isolated with much more ease than normal. It will be an interesting few years:
The rapid progress in dog genetics is prompting some researchers to get back to studies that motivated a canine genome project in the first place: tracking down genes associated with behavioral traits. Neff has teamed up with Illumina Inc. in San Diego, California, to use a microarray to look for SNPs associated with "pointing." About 40 breeds point--freezing and lifting a paw in the direction of a rabbit or other quarry. "I finally feel we have a chance to understand the behavior," says Neff, who worked with Rine in the 1990s. Labels: Genetics
In the middle of an otherwise boring New Yorker article about where to buy coats for the coming winter, I came across this passage, describing the author's (possibly tongue-in-cheek) search to understand why she seems to feel cold more acutely than other people:
I called Dr. Andrej Romanovsky... to ask how the body detects cold. According to Romanovsky, the going theory is that a newly discovered receptor (TRPM8, if you were wondering [I was!]) reacts to low temperatures. This same molecule also reacts to menthol, which accounts for the compound's cool feel on the skin. So why is it that certain people whine more than others when the temperature drops? "I don't think anybody studies what you want them to study, " Romanovsky told me.Not true, Dr. Romanovsky! Sometimes people study exactly what you want them to study. I googled my way to this study, entitled "Genetic predictors for acute experimental cold and heat pain sensitivity in humans": Background: The genetic contribution to pain sensitivity underlies a complex composite of parallel pain pathways, multiple mechanisms, and diverse inter-individual pain experiences and expectations.Ok, these associations are highly questionable (anyone want to fund a large genome-wide association study of cold tolerance to put the question to rest?), but still, there are scientists asking these sorts of questions. I also checked out a couple of the genes in Haplotter-- selection for cold tolerance was likely very strong as humans moved north out of Africa. There are some perplexing signals-- TRPM8 shows some evidence for selection, but in the Yoruba (Nigeria: probably not exerting a selection pressure for increased cold tolerance). TRPV1 (a receptor involved in heat tolerance) shows a huge signal in the Yoruba as well; this makes more sense. Nothing too exciting, I just was amused that my furious googling was inspired by an article about coats in the "style issue" of the New Yorker. And contrary to Dr. Romanovsky's claim, understanding why people feel cold differently is very much an active area of research (and well within the reach of current technology). Labels: Genetics, Population genetics
I posted recently on the Flynn Effect, and some interesting papers on the subject came to my attention afterwards.
First, there is a review of Flynn's recent book by Richard Lynn in Intelligence, 2007, (35), 515-16. Lynn defends his own nutritional explanation of the Flynn Effect against various criticisms. He points out that it is one of the few theories that can explain an increase in IQ among young children. A more substantial piece was mentioned in comments on my post. For several years M. Mingroni has been arguing that heterosis ('hybrid vigor') has played a major part in the Flynn Effect. This makes him unusual in proposing a mainly genetic, rather than environmental, explanation. His latest paper is in Psychological Review, 2007, 114(3), 806-29. An abstract is available here. The first part of the paper criticises existing explanations such as nutrition, schooling, etc. Mingroni makes some good points, but I think that he and some others make the mistake of assuming that there has to be a single, or at least a main, explanation of the Flynn Effect. If the Flynn Effect were substantially uniform across all tests, all age groups, all countries, etc, this would be a reasonable assumption, but it isn't that uniform. There is no more reason to expect to find a single explanation of rising IQ scores than of rising life expectancy. The Flynn Effect might be due to a bit of nutrition, a bit of schooling, a bit of heterosis, a bit of audiovisual stimulation, and other factors, in various proportions in different times, places, and age groups. I'm all in favour of simple explanations where they work, but we should not always expect them to. [Added on 24 September: Of course, all the various suggested factors - nutrition, schooling, heterosis, etc - are ultimately due to economic growth, but it would not be helpful to identify 'economic growth' as the 'cause' of the Flynn Effect, any more than of increasing life expectancy. We want something more specific. ] The second part of Mingroni's paper is more constructive, and sets out a model for examining the effects of heterosis. I discuss it further below the fold, but I should stress now that Mingroni does not prove (or even claim to prove) that heterosis accounts for a large part of the Flynn Effect. Using plausible parameters his model only accounts for an increase of 2 to 5 points in mean IQ, which is less than a quarter of the cumulative Flynn Effect. The possibility of heterosis increasing IQ scores is not controversial. Close inbreeding (e.g. cousin marriage) usually reduces the IQ of the offspring. This suggests that some genes for low IQ are recessive. Conversely, genes for higher IQ are probably often dominant. If so, then for any given set of underlying gene frequencies in the population, the mean IQ will be higher when the proportion of heterozygotes is higher. Random mating will therefore produce higher mean IQ than inbreeding, which for this purpose includes not only inbreeding in the traditional sense, but also breeding confined within subpopulations. If gene frequencies within such subpopulations vary, then the proportion of homozygotes will on average be higher than if the subpopulations were merged together in a random-mating total population. If subpopulations are geographically or otherwise isolated from each other, they will evolve differing gene frequencies as a result of genetic drift or differential selective pressures. Over the last few centuries the population structure in many countries has changed in such a way as to break down such isolation. Small communities have been absorbed into larger towns, much of the rural population has migrated into cities, and improved transport has mixed up populations within the same countries and even internationally. It is therefore reasonable to hypothesise that heterosis has made some contribution to the Flynn Effect. The question is how much. Mingroni's paper develops a model to explore this question. I can only give a rough outline here. It is assumed that a large number of loci affect IQ, with two alleles at each locus. The population is assumed to be initially subdivided and then merged into a single random-mating population. The variable quantities are the number of loci, the degree of dominance, the frequency of each allele in the total population, and the amount of increase in heterozygosity assumed to take place as a result of changing population structure. Values are assigned to genotypes in accordance with the degree of dominance, and gene frequencies for each allele are assigned stochastically to each locus within the subpopulations. The initial mean and standard deviation of IQ in the population resulting from the model is calculated and scaled to have a mean of 100 and s.d. of 15. The effect of the postulated change in heterozygosity on the mean and s.d. of IQ is then derived for a range of values for the key variables. The choice of values is determined in part by plausibility and in part by empirical data. It is assumed that the number of relevant loci is either 50, 75 or 100. The dominant homozygote has the value 1, the recessive homozygote has the value 0, and the heterozygote has the value .6, .8 or 1 according to the degree of dominance. The population frequency of the recessive allele at each locus is either .4, .5, or .6. The increase in heterozygosity resulting from merging the subpopulations is either .02, .03, or .04; that is, between 2 and 4 percent. (These figures are based largely on Cavalli-Sforza's classic studies on isolated Italian villages in the late 1950s.) With these assumptions Mingroni obtains increases in mean IQ ranging between 1.2 and 5.1 IQ points, with most results falling between 2 and 4 points. These changes are much smaller than the observed cumulative Flynn Effect, but Mingroni argues that the total change in heterozygosity at a national level might be much larger than those suggested by the Italian data. Opinions will differ on the plausibility of this. Personally, I would be sceptical. Cavalli-Sforza chose his Italian villages to represent a relatively isolated pattern of settlement and marriage, in order to give genetic drift a chance to show itself. I doubt that the traditional degree of isolation would be as large as this in many parts of Europe. (The degree of inbreeding might be higher in some non-European societies, especially where cousin-marriage is common.) It is possible to calculate the initial difference in allele frequencies needed to produce a given increase in heterozygosity when the subpopulations are merged. For two equal subpopulations, and two alleles at a locus, the increase in heterozygosity produced by merging the subpopulations, as a percentage of the population, is (D^2)/2, where D is the difference in allele frequencies between the subpopulations. [Note] To produce an increase greater than Mingroni's upper figure of 4 percent the differences between subpopulations have to be quite large, e.g. a difference of around 30 percent in allele frequencies. This is larger than the usual differences between European nations, let alone different parts of the same nation. If there are more than two alleles the differences in allele frequencies have to be even larger. For example, if the subpopulations have 3 alleles at a locus, with frequencies of .2, .4, .4 in one subpopulation, and .1, .6, and .3 in the other (an aggregate difference of 40 percent), the effect of merging the subpopulations would only be to increase heterozygosity at the locus from .59 to .605. (If there are more than two subpopulations, a multi-allele system would have more scope, as each allele might be concentrated in a different subpopulation, but the differences in frequency between subpopulations would still have to be large to make much impact.) In Mingroni's simulations an increase of 1 percent in heterozygosity produces an increase of about 1.1 points in the mean IQ of the population. The increase seems to be linear, as it should be, since each substitution of heterozygotes for homozygotes adds a fixed amount to the total IQ 'score' of the population. A cumulative IQ increase of around 20 points therefore requires an increase in heterozygosity equivalent to around 18 percent of the population. This requires a huge initial difference in allele frequencies - around 60 percent - larger than the usual difference between continents. I also see a problem with the timing of the changes. In the first countries to industrialise, much of the breakdown in traditional population structure occurred in the 18th and 19th centuries. To take the most obvious example, in Britain some 90% of the population already lived in large towns and cities by the end of the 19th century. The scope for further increases in heterozygosity during the 20th century (excluding interracial mating) must have been quite small. Yet the Flynn Effect has been much the same in Britain as elsewhere. Then there are those populations founded by immigrants. The best example is perhaps Australia. From the beginning of white settlement around 1800, the population of Australia was drawn from all over the British Isles (and contrary to myth, only a small proportion were convicts). If Mingroni is right in believing that heterosis can account for the bulk of the Flynn Effect, we would expect Australia to have had a spectacular one-off increase in IQ compared with the parent population. I mean no disrespect to Australia if I say that this has not been observed. Much the same argument can be applied to New Zealand and Anglophone Canada. The United States is a more complex case, as settlement extended over a longer period, and involved a variety of European groups who settled to some extent in different areas (Germans in Pennsylvania, Scandinavians in Minnesota, etc.) There could be parts of the United States where populations were quite inbred and the scope for heterosis was correspondingly large. But there must also have been areas (e.g. California and other west coast states) where the white population was well-mixed from the beginning of settlement. This would leave little scope for further IQ gains from heterosis. These are fairly obvious difficulties, but I cannot see that Mingroni addresses them Note: Suppose the frequency of one allele in the total population is M. The frequency of the other allele is therefore (1 - M). Under random mating in the total population the proportion of heterozygotes will be 1 - M^2 - (1 - M)^2 = 2(M - M^2). Now suppose the population is divided into two equal subpopulations, A and B. If the frequency of one allele in A is (M - d), the frequency of the other allele must be (1 - M + d), while the corresponding frequencies in B are (M + d) and (1 - M - d). Under random mating within each subpopulation the average proportion of heterozygotes will be [1 - (M - d)^2 - (1 - M + d)^2 + 1 - (M + d)^2 - (1 - M -d)^2]/2 = 2(M - M^2 - d^2). This is 2d^2 less than under random mating in the total population. The amount 'd' is here the difference between the frequencies of each allele in the subpopulations and the mean for the total population. The difference in frequency of the same allele between the two subpopulations is 2d. If we set D = 2d, then 2d^2 = (D^2)/2. So it is easy to calculate the increase of heterozygosity (measured as a proportion of the population) resulting from the merger of the subpopulations for a given difference in allele frequencies, and the associated increase of IQ e.g.: D...........(D^2)/2..........IQ points gain 0.1............0.005...........0.6 0.2............0.02............2.2 0.3............0.045...........5.0 0.4............0.08............8.8 0.5............0.125..........13.8 0.6............0.18...........19.8 0.7............0.245..........27.0 These figures are independent of the value of M, but there are constraints on the possible values of D. E.g. if M is .8, D cannot be greater than .4, since M + D/2 cannot be greater than 1. There are of course many simplifying assumptions, so the figures should not be taken too seriously. Labels: IQ
Thursday, September 20, 2007
New paper out in PLOS Genetics, PCA-Correlated SNPs for Structure Identification in Worldwide Human Populations:
Genetic markers can be used to infer population structure, a task that remains a central challenge in many areas of genetics such as population genetics, and the search for susceptibility genes for common disorders. In such settings, it is often desirable to reduce the number of markers needed for structure identification. Existing methods to identify structure informative markers demand prior knowledge of the membership of the studied individuals to predefined populations. In this paper, based on the properties of a powerful dimensionality reduction technique (Principal Components Analysis), we develop a novel algorithm that does not depend on any prior assumptions and can be used to identify a small set of structure informative markers. Our method is very fast even when applied to datasets of hundreds of individuals and millions of markers. We evaluate this method on a large dataset of 11 populations from around the world, as well as data from the HapMap project. We show that, in most cases, we can achieve 99% genotyping savings while at the same time recovering the structure of the studied populations. Finally, we show that our algorithm can also be successfully applied for the identification of structure informative markers when studying populations of complex ancestry. The text has the nitty-gritty for now many SNPs are needed for them to generate the population clusters. They seem to be selling the method on a "faster, cheaper" spin. Jump to the discussion though and something interesting does pop out that doesn't require mediation upon the uses of orthonormal vectors: Our findings demonstrate that to a large extent, SNPs identified as structure informative in one geographic region are not portable for the analysis of populations in a different geographic region, suggesting that the forces that shaped population structure in each geographic region have influenced different parts of the genome. However, analyzing jointly nine populations from around the world and 9,160 SNPs, we showed that using 50 PCA-correlated SNPs we can assign the studied individuals with 100% accuracy to their population of origin.... What could those forces be? You can connect the dots. Finally, a small detail which I thought was interesting: ...As we have shown here, analyzing two independent Puerto Rican datasets, PCA-correlated SNPs can be successfully used to reproduce the structure of admixed populations and predict the ancestry proportions of the studied individuals. Interestingly, we found that interindividual variation across the Native American axis in the Puerto Rican samples that we studied was very low, perhaps depicting the fact that admixture with Native Americans occurred very long ago, and was random over several generations. This seems to make sense, the Taino were absorbed into the Puerto Rican population in the 16th century. Subsequent to this there were hundreds of years of African and European immigration to the island. Nevertheless, a substantial proportion of the mtDNA lineages in Puerto Rican are Amerindian, which implies that the Europeans and Africans were disproportionately male (otherwise European and African mtDNA lineages would have slowly replaced the Amerindian ones over time). Labels: Genetics, human biodiversity
Wednesday, September 19, 2007
Nicholas Wade of the New York Times is, without a doubt, one of the best science reporters in America. Apart from his writing, which is of course excellent, he shows an impressively deep knowledge of his chosen subject (genetics)-- enough to write an excellent book on the topic and to effectively communicate subtle aspects of research (when he mentioned statistical power in a recent article, I may have choked up a little bit. It was really that beautiful).
So if you were, say, writing an article criticizing the coverage of genetics in the media, Wade should be absolutely the last person on the list of people to mention. However, a new article in Nature Reviews Genetics takes him to task for one of his uses of he word "race". Needless to say, I think it's absurd. From the article: An example of the constant slippage of race terms is provided by Nicholas Wade, who was a strong journalistic propagator of Neil Risch's claim that there are five major human races that are defined by genetic clusters, specifically, Africans, Caucasians, Asians, Pacific Islanders, and Native Americans. However, when reporting on recent diabetes research, Wade includes as his list of races, "African-Americans, Latinos, American Indians, and Asian-Americans." The social grouping we call Hispanics is not one of Risch et al.' s categories, and it does not share a stable, historically deep genetic cluster.First, perhaps I'm being overly sensitive about tone here, but on first reading this passage seemed to make Risch and Wade sound, I don't know...a little sinister. The "claim" being "propagated" by Wade is the simple fact that there is some clustering of genetic diversity according to broad geographic regions. Risch has long advocated (convincingly, in my opinion) that this genetic diversity not be ignored in medicine. Perhaps the public is interested in hearing about this research. Second, the list of "races" given by the author is a little silly. Risch has never made some kind of statement about which genetic clusters are "races" and which are not. In fact, I'm guessing the author of this paper hasn't read much of Risch's work. In a 2002 paper, he does indeed write, referring to a number of studies on the genetics of race: Effectively, these population genetic studies have recapitulated the classical definition of races based on continental ancestry - namely African, Caucasian (Europe and Middle East), Asian, Pacific Islander (for example, Australian, New Guinean and Melanesian), and Native American.But these clusters are not the only way to apportion genetic diversity, of course. Race is, to a certain extent, a social construct. How much genetic clustering do current social groupings (including the dreaded word "Hispanic") show? A good question, and luckily one Risch answered in a 2005 paper: Subjects identified themselves as belonging to one of four major racial/ethnic groups (white, African American, East Asian, and Hispanic) and were recruited from 15 different geographic locales within the United States and Taiwan. Genetic cluster analysis of the microsatellite markers produced four major clusters, which showed near-perfect correspondence with the four self-reported race/ethnicity categories. Of 3,636 subjects of varying race/ethnicity, only 5 (0.14%) showed genetic cluster membership different from their self-identified race/ethnicity.So if one is using the word "race" as defined by the options available when you check a box on a government form, races do indeed show some extent of genetic clustering. And for the record, here's the Wade quote that so exemplifies nefarious use of the word "race": While Type 2 diabetes is more common in African-Americans, Latinos, American Indians, and Asian-Americans, Dr. Stefansson said more studies were needed to see whether there were significant differences in the variant gene's distribution among races.Sounds pretty reasonable to me. Labels: Population genetics
I've referred to Virpi Lummaa's research on the Grandmother Hypothesis using Finnish records a fair amount, check out this new paper (Open Access) using Gambian data. There are other papers and studies (use books.google.com for this) among groups like the Khasis and Bengalis (Khasis = matrilineal & matrifocal, Bengalis = patrilineal & patriarchal, but both show maternal grandmother effect). Generally the results are often ambiguous, but what directionality there is in the data implies some relationship between maternal grandmothers and fitness. Most workers have a pretty straightforward interpretation that the bias toward maternal grandmothers taking an interest in their grandchildren, but less so paternal grandmothers, is a function of past human mating patterns. There has long been debate about whether patrilocality or matrilocality was more the norm genetically (early genetic data implied the former, more recent work has clouded the issue). Ethnographic surveys from anthropology tend to show a bias toward patrilocal, and often patrilineal cultures. But, there is also a tendency to see these features more often in "large scale" as opposed to "small scale" cultures (and historical records show a shift from matrifocality toward patrifocality as societies become more "civilized," e.g., Japan or Southern India). I have alluded to the fact that I believe that the last 10,000 years and the Neolithic Revolution resulted in the emergence of new and often constraining cultural adaptations, I believe that normative patrifocality is one of those.1 Though I do believe in the power of recent human evolution, I think that time lag is probably more likely in something as complex and contingent as the physiological of menopause and the evolutionary logic which drove it (just like romantic love, which was also quite often an irrelevancy or obstacle for high status lineages for whom mating was a material exchange between consenting cartels).
1 - Indo-European cultures often alluded to a special affectionate role for the maternal uncle. And yet note that nominally they were generally patrilineal cultures. This is one case where action and theory might have varied systematically. Labels: Evolutionary Psychology
Monday, September 17, 2007
Alex Palazzo gives a nice summary of a recent paper (open access) on adaptation in non-coding elements in mammals. The paper was mentioned briefly by Razib here.
Labels: Population genetics
John Hawks has a series of great quotes from a 1963 article by Dobzhansky on the interplay between genetic and cultural evolution. How about this:
Being an anthropologist only by avocation, I may perhaps venture to claim for anthropology more than most anthropologists dare claim for themselves. The ultimate function of anthropology is no less than to provide the knowledge requisite for the guidance of human evolutionRather ambitious, no? Labels: Genetics, Human Evolution
I didn't smoke out any interesting correlations in the GNXP Survey. For example, can you believe that those with more education tend to be of higher economic status? Assman was right, my questions were rather boring, so the analysis was going to yield boring as well. In any case, I've put the survey results up as a cross-tab text file in GNXP Forum Files if you want to play with it. N = 449. Long time readers will note relative stability in the profile of users on the site. The only thing I will offer is this:
How long have you been reading GNXP? Male, N = 384 1 month to 1 year 28.65% 1 year to 3 years 42.45% 3 years to 5 years 22.66% Since the beginning 6.25% Female, N = 63 1 month to 1 year 36.51% 1 year to 3 years 42.86% 3 years to 5 years 20.63% Since the beginning 0.00% Some have suggested we have erosion of female readership because of the sexism. What do you think? I think the N's are small, and the blogosphere was much more male in 2002. Labels: Blog
On this site, there is often speculation about population differences in various phenotypes, and the role of genetics and natural selection in said differences. Hypotheses are lovely and all, but luckily there are publicly available resources that anyone can access and browse to determine whether their hypothesis has any empirical support. In this post, I provide a basic introduction to those resources. I note here that, given the rapid progression of knowledge in the area, this is likely to remain state-of-the-art for, oh, a couple months, tops.
I. Allele frequency resources  To start, let's say you have a hypothesis about the role of gene X in phenotype Y. If populations have different distributions of Y, you might also expect them to have different distributions of alleles of X, no? Seems reasonable. Unfortunately, there's no resource of population allele frequencies available (though one might expect this to change in the near future). The best things available now are the HapMap (which has genome-wide allele frequency information on four populations-- a western European population, the Yoruba from Nigeria, the Han Chinese, and a Japanese population from Tokyo) and ALFRED (a mishmash of allele frequency data compiled from various small studies). To see what these databases can do for us, let's take an example: perhaps you have heard of this trait called lactose tolerance, and a gene called lactase (LCT). The two SNPs (single nucleotide polymorphisms) that are putatively causal for lactose tolerance (ie. that allows one to digest lactose in adulthood) are located ~14000-20000 base pairs upstream from LCT, in an intron of a gene called MCM6. Let's check ALFRED to see if anyone has assembled allele frequency data on these SNPs. From the front page, I enter MCM6 in the quick search area (note I don't enter LCT, since the causal SNPs are actually in MCM6), and follow the link to the page for MCM6. The two SNPs I'm looking for are "intron 13 (C/T)" and "intron 9 (G/A)". If I click on, for example, the intron 9 SNP, I get to the entry for that SNP, where I can generate a map like the one on the right, or peruse the frequencies in table form. As seems reasonable, the T allele is common in Europeans and some Central Asian populations, but nearly absent elsewhere.  Of course, most SNPs aren't going to be in this database (I actually generally don't use ALFRED at all--any new SNP you're interested in isn't going to be in it), so let's do something similar with the HapMap. To do that, we note the intron 13 SNP is named rs4988235 (you can see this in ALFRED, but usually you won't need to--almost all SNPs are now referred to in all databases and papers by their rs number, which is standardized way of referring to SNPs). From the HapMap homepage, I click on the link to the genome browser (either one will do), and enter "SNP:rs4988235" in the "Landmark or Region" field. This brings me to the area, and one of the tracks of the browser gives the allele frequencies, as seen on the right. Again, Europeans (labeled CEU) have high frequency of the causal allele, which is absent elsewhere. II. Selection resources 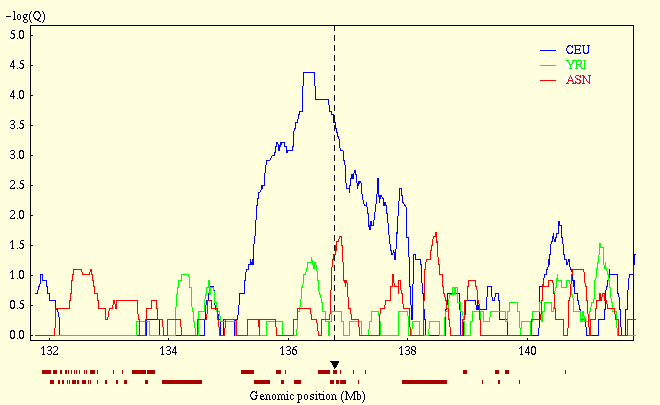 So alleles controlling the expression of LCT show population frequencies in line with explaining the differences in the distribution of lactose tolerance worldwide (to a rough extent). Now, could those alleles be under natural selection? To test this, we turn to Haplotter, a database of summary statistics designed to test for recent positive selection. The underlying data is from the HapMap, so only three populations are available (here, the Chinese and Japanese are condensed into a single Asian population). The summary statistics calculated are iHS, D, H, and FST. I don't intend to give a full exposition of what each of these statistics is, but briefly, iHS is a summary statistic of the haplotype structure surrouning a region, which has power to detect selective sweeps that are incomplete, D and H are summary statistics of the frequency spectrum that have power to detect sweeps that are complete/nearly complete, and FST is a measure of allele frequency differentiation between populations. So let's take a look at LCT (in this case, since the statistics are calculated on a region, we could look either at LCT or MCM6). From the Haplotter home, I enter "LCT" in the "Query by gene" area, which brings up a number of plots. The relevant statistic here is iHS, as the alleles we're interested in are still polymorphic (see the figures above). On the right, you see the iHS plot for the region. Clearly, the European population (the blue line) has extraordinarily elevated values, and the Yoruban and Asian composite populations do not. This could be interpreted/has been interpreted to demonstrate a very strong selection on the ability to digest lactose in our recent history. Like I said, these resources will likely be obsolete soon, but for now they're fun places to browse and test various hypotheses with. So take your favorite gene, look for selection on it in Haplotter, check the allele frequency differences in the HapMap, and hey, don't be afraid to tell us what you find. Addendum from Razib: The comment thread below is also going to be an "open thread." You can see it to the top right in the sidebar as Find any genes?. If you think you've found something interesting through these resources, post it there! There are only a finite number of eyes looking at these heaps of data (or brains writing lines of code to analyze them), so there's no downside in adding some more.... Labels: Genetics, Population genetics
Sunday, September 16, 2007
I finally had a chance recently to read the Venter genome paper, purportedly a landmark in personalized medicine. The short version of my thoughts: there's a long way to go.
Most of the paper is a straightforward list of the characteristics of Venter's genome-- it's different than the reference genome in a number of places, has some insertions, some deletions, and some inversions, all duly noted. And if the people quoted in the New York Times are to be believed, the quality of this new human genome assembly is quite high, better than the current reference sequence, which is a major contribution in and of itself. The authors emphasize two things in this paper-- the attempt to separate Venter's chromosomes into haplotypes-- a paternal and maternal chromosome-- and the role of genome sequencing in associations studies. And I agree: sequencing, it is likely, will be the tool of choice for both of these applications in the future (as opposed to haplotype reconstruction from population data and SNP genotyping arrays). However, this paper makes it clear the technology simply isn't there yet. In a comparison of SNPs typed by sequencing with those typed with a SNP array, they find a whopping 9% error rate (SNP arrays now have error rates on the order of 0.1%, for comparison). Most of the miscalled positions are heterozygous, meaning that rare SNPs are likely to be missed. For a platform that seeks to remedy the bias towards common SNPs in current technologies, this is not good enough. In terms of haplotype reconstruction, the authors make a number of dubious claims about the importance of their advances. It is not true, as stated in the introduction, that genome-wide association studies rely on phased haplotypes for analysis. In fact, most of the ones I have seen do nothing more than simply count up genotypes at each SNP in cases and controls and perform a chi-squared test. In most cases, haplotype-level analysis is simply not done. This may change in the future, of course, but it's difficult to see how what they've done (note they aren't even able to make ideal haplotype inference with the data) is that exciting. Again, though, advances here could end up being very important in the field. Finally, the "personalized medicine" portion of the paper is weak. This is largely due to the fact that not much is known about the genetics of medically-relevant traits, but the authors simply provide a list of alleles known to play a role in phenotypes, and Venter's genotype at that position. There's not much more that can be done at this point, but still, it's not particularly of interest (unless you want confirmation that Venter indeed has blue eyes, as predicted by his OCA2 genotype). All this said, this paper is indeed a first blind stab towards personalized medicine, and I'm glad someone is putting all this information out there. A number of people have raised ethical concerns about research like this (John Quackenbush, for example, a highly respected and respectable genomicist, has seemingly created a website explicitly for airing his views on Venter's ethics). In all seriousness, they suggest that someone should need approval from an Institutional Review Board to make public their own genome. While I'm sure IRBs would love to have the power to control information like that (see IRB Watch for various examples of the "mission creep" of IRBs), it's simply absurd, and the suggestion says more about people's distaste for Venter than anything else (when you can't criticize someone on scientific grounds, bust out the ethics card). I look forward to having more people make their genomes public-- only with more information can better diagnostics be made. Labels: Genetics
Carl Zimmer has a post up on copy number variation and gene duplication. Via evolgen.
Labels: Genetics
Friday, September 14, 2007
In his September 14, 2007 op-ed piece in the New York Times, David Brooks tells his impression of the latest research in cognitive ability. Unfortunately, he not only misses the forest, but he bungles a few trees as well. Article and comments below.
A nice phenomenon of the past few years is the diminishing influence of I.Q. Right out of the block he is off. In what domain was there once a non-zero IQ-outcome relation, but now, X number of years later, the relation has shown a systematic decrease? From the generality of the statement, one would expect this to hold across most, if not all, pertinent domains (e.g., occupation, academic success, etc.). However, that is not the case. Not only do the IQ-achievement, and IQ-occupation relationships still hold, but now there is a burgeoning new field in the area: cognitive epidemiology, that looks to see how health outcomes are related to cognitive ability. Deary et al give a terse summary here, and Gottfredson gives a conceptual overview here. But, perhaps more interesting, researchers who have no interest in intelligence per se are finding similar results: a case-in-point is Yakov Stern's cognitive reserve research that shows people with higher IQ scores tend to have have less severe symptoms of Alzheimer's symptoms. As this is a new area of inquiry, the exact nature of the relationship has not been identified, but one thing we can say for sure is that there is no diminishing influence of cognitive ability. For a time, I.Q. was the most reliable method we had to capture mental aptitude. People had the impression that we are born with these information-processing engines in our heads and that smart people have more horsepower than dumb people. These two statements have little to do with each other. IQ (at least as derived from a Full Scale score) has been, and still is, very reliable for most age groups and subpopulations, no matter how you measure reliability. For example, the Woodcock-Johnson, one of the more theoretically sound measures of cognitive ability, reports in their new normative update that the coefficient alpha values (which are a lower bound of reliability) above .90 for all ages ranging from 3 to over 80. Given that the maximum value alpha can take is 1 (under almost all circumstances), this is pretty good evidence. If you look at the technical manual for the Wechsler, Stanford-Binet, or Reynolds Intellectual Assessment Scales, you'll find very similar values (I refer to these only because their norms span a very large age group, and the full scale score is derived from multiple subtests). I challenge Mr. Brooks to find a more reliably-measured psychological construct in psychology, nay, in the social sciences. The second statement, while perhaps overstated, is true. People are born with brains, these brains process information, and smarter people (as measured by IQ scores) tend to process information faster (see, for example, here and here). What impression should people have instead? People are born with a blank slate and all of life is little more that the acquisition of stimulus-response patterns? Skinner died in the 1990s, and strict adherence to this view died long before that (a great book about this). And in fact, there's something to that. There is such a thing as general intelligence; people who are good at one mental skill tend to be good at others. This intelligence is partly hereditary. A meta-analysis by Bernie Devlin of the University of Pittsburgh found that genes account for about 48 percent of the differences in I.Q. scores. There's even evidence that people with bigger brains tend to No disagreement here. But there has always been something opaque about I.Q. In the first place, there's no consensus about what intelligence is. Some people think intelligence is the ability to adapt to an environment, others that capacity to think abstractly, and so on. Ah, the slippery slope begins. These arguments are so old, and well-answered in the literature that it is almost painful to repeat them. I refer the interested (and Mr. Brooks) to Seligman's phenomenal, non-technical introduction, as well as Deary's brilliant literary corpuscle. First, IQ and intelligence are two different things. One is a measuring instrument's scale and the other is a psychological construct that is measured, to one degree or another, by an IQ test. We don't confuse inches and paper, so why do we confuse IQ and intelligence? Second, few scholars actually study intelligence. While the word might be used in common parlance, there is no common definition. Instead, most serious scholars study general intelligence (g) or one of its sub-constructs (e..g, fluid abilities, crystallized abilities; see here or here or here). Once you make the jump to g, the definition becomes much more consensual. There are technical debates (as there are in any branch of science), but it's measurement (by factor analysis of one flavor or another) is virtually undebated. For most purposes in daily life, it is OK to quasi-equate intelligence and g, as well as IQ scores and intelligence, but they really are quite different concepts. Then there are weird patterns. For example, over the past century, average I.Q. scores have risen at a rate of about 3 to 6 points per decade. This phenomenon, known as the Flynn effect, has been measured in many countries and across all age groups. Nobody seems to understand why this happens or why it seems to be petering out in some places, like Scandinavia. IQ scores, across generations, need re-calibrated for valid comparisons. We have ways that do this very well (latent trait models), that have very sound theory behind them. You have to periodically re-calibrate your bathroom scale, and you have no question about what it is measuring; why should IQ be any different? As a side note, this phenomenon is not at all confined to IQ tests, and it has been known about in the psychometric literature for decades, although it is called item parameter drift there. Moreover, just because there is no consensus as to why cross-generational scores tended to rise in the mid-twentieth century, this does nothing to invalidate the validity of interpreting IQ scores within a generation. I.Q. can also be powerfully affected by environment. As Eric Turkheimer of the University of Virginia and others have shown, growing up in poverty can affect your intelligence for the worse. Growing up in an emotionally strangled household also affects I.Q. One of the classic findings of this was made by H.M. Skeels back in the 1930s. He studied mentally retarded orphans who were put in foster homes. After four years, their I.Q.'s diverged an amazing 50 points from orphans who were not moved. And the remarkable thing is the mothers who adopted the orphans were themselves mentally retarded and living in a different institution. It wasn't tutoring that produced the I.Q. spike; it was love. Brooks is telling all parents of children who have Mental Retardation or Borderline Intelligence that their children's low cognitive ability is a direct result of parental inadequacy. If these parents would love their children more, the Mental Retardation would go away. If I were king, I would mandate that any person with the gumption to make asinine statements like this do two things (a) read Spitz's chef d'oeuvre, and (b) spend a week with a family who have a child diagnosed with Mental Retardation. Not just a daily visit, but an in vivo experience. Then get back to me about how easy it is raise the cognitive ability of people with mental retardation. By the way, Turkheimer's studies look at the ability of the environmental variance to modify heritabilty estimates. Specifically, people who grow up in more impoverished environment have a more variable environments, which, almost by definition, decreases heritability estimates. This is a very long cry from showing "growing up in poverty can affect your intelligence for the worse". Then, finally, there are the various theories of multiple intelligences. We don't just have one thing called intelligence. We have a lot of distinct mental capacities. These theories thrive, despite resistance from the statisticians, because they explain everyday experience. I'm decent at processing words, but when it comes to calculating the caroms on a pool table, I have the aptitude of a sea slug. What? A few paragraphs ago general intelligence existed, now it doesn't? Anyway, it is an awful shame when everyday experience does not map onto what data tell us: Beth Visser recently (gasp!) gathered data to test Gardner's theory. What did she find? Basically what John Carrol said she would find a decade ago: these multiple intelligence all positively correlate (sans kinesthetic intelligence) and a strong g factor can be extracted when the measures are factor analyzed. I.Q., in other words, is a black box. It measures something, but it's not clear what it is or whether it's good at predicting how people will do in life. Over the past few years, scientists have opened the black box to investigate the brain itself, not a statistical artifact. I wish I had the luxury of being able to write blatantly false statements in a national paper. There is over 100 years of empirical literature investigating the construct validity of IQ. There is also 100 years of literature examining what, and how well, IQ scores predict life outcomes. A simple perusing of Jensen's g factor or Brand's g factor (this one is even available for free!) would have sufficed here; but who wants data to interfere with a good opinion? Now you can read books about mental capacities in which the subject of I.Q. and intelligence barely comes up. The authors are concerned instead with, say, the parallel processes that compete for attention in the brain, and how they integrate. They're discovering that far from being a cold engine for processing information, neural connections are shaped by emotion. ...and you can read books about journalism in which the subject of sophism barely comes up. Namely because the books are concerned about journalism, not logical arguments. Why would a cognitive scientist who is writing a book about attention necessarily include a chapter about intelligence? As a rule, cognitive scientists tend to be concerned with general processes, not individual differences. The field can learn much from each other, but they are concerned about very different areas of investigation. Antonio Damasio of the University of Southern California had a patient rendered emotionless by damage to his frontal lobes. When asked what day he could come back for an appointment, he stood there for nearly half an hour describing the pros and cons of different dates, but was incapable of making a decision. This is not the Spock-like brain engine suggested by the I.Q. By all means, lets infer from one person with severe brain damage to the entire population. But if we want to play this game, I had a patient once who had just started Kindergarten, but could do addition, subtraction, multiplication and long division (the latter of which he deduced how to do pretty much on his own). He did not need a school to teach him any of this, so lets get rid of elementary schools for everyone. After all, if my patient could figure out long division, so should every other 5 year old. Today, the research that dominates public conversation is not about raw brain power but about the strengths and consequences of specific processes. Daniel Schacter of Harvard writes about the vices that flow from the way memory works. Daniel Gilbert, also of Harvard, describes the mistakes people make in perceiving the future. If people at Harvard are moving beyond general intelligence, you know something big is happening. Harvard never was a bastion for the study of general intelligence. It was the University of London. In fact, except for Yerkes, Herrnstein, and, to some extent, Pinker, I can't think of too many profs. there who contributed much to the study of general intelligence. And since when did Harvard's Psychology department become the measuring stick by which the importance of a research agenda was measured? I'm sure much of the work they do there furthers the general field of psychology, but what makes their research more special than, say, Berkeley, Stanford, UT-Austin, etc.? The cultural consequence is that judging intelligence is less like measuring horsepower in an engine and more like watching ballet. Speed and strength are part of intelligence, and these things can be measured numerically, but the essence of the activity is found in the rhythm and grace and personality — traits that are the products of an idiosyncratic blend of emotions, experiences, motivations and inheritances. This paragraph is quite confusing, perhaps due to the mixing of automotive and ballet metaphors. I think Brooks is trying to tell his readers he thinks personality is important for modern culture. I agree. And that has absolutely no bearing on the importance (or lack thereof) of cognitive ability in the same culture. Recent brain research, rather than reducing everything to electrical impulses and quantifiable pulses, actually enhances our appreciation of human complexity and richness. While psychometrics offered the false allure of objective fact, the new science brings us back into contact with literature, history and the humanities, and, ultimately, to the uniqueness of the individual. What? First, psychometrics (and specifically, the study of cognitive ability) has always held as paramount the uniqueness of the individual. Second, how has the study of cognitive ability NOT shown the complexity of humanity? Sir Cyril Burt, one of the pioneers in the field, was enamored with the complexity of students he encountered while a school psychologist in London. In fact, he was such an ardent supporter of psychological measurement so that he could begin to quantify, and, ultimately, understand and predict, this variability(see a bibliography here). More modern techniques, such as fMRIs, extend the work of psychometrics, in that they add to our ability to quantify individual variability at a much more precise level. However the two are quite complementary. From here: Despite the sometimes contentious controversy about whether intelligence can or should be measured, the array of neuroimaging studies reviewed here demonstrates that scores on many psychometrically-based measures of intellectual ability have robust correlates in brain structure and function. Moreover, the consistencies demonstrated among studies further undermine claims that intelligence testing has no empirical basis. In the world of academia, to have your ideas printed in a reputable journal, you have to go through the peer-review process. While there are arguments for the pros and cons of this process, at least it frequently squashes ill-informed, blatantly false propaganda from reaching the masses. After reading op-ed like this, one wishes the NYT had a similar mechanism in place. Labels: David Brooks, general intelligence, IQ
About a week ago I posted on a new paper about worldwide variation on a gene which results in differences in muscle fiber. The author left a comment, which I'll reproduce below:
We thought about selection for cold tolerance, but our latest data on global distribution of the null allele don't really fit with that. Most likely it's something to do with famine resistance, although we're not ruling out the idea that it's selection for some sort of muscle performance phenotype (it's surprising how many muscle genes are popping up in recent genome-wide scans for selection). Labels: Genetics
Last week I talked about the fact that a significant proportion of the within population variance of skin color in South Asians is due to a mutant allele which is also responsible for a significant fraction of the between population difference for Europeans and Africans. This mutant allele on SLC24A5 has gone to fixation within the last 10,000 years in Europeans, and increased to great proportions along a broad great swath of southwestern Eurasia and into northern Africa. What's going on here? A friend commented, "Well, it isn't like there is going to be Vitamin D deficiency in India." That seems plausible enough...except I just stumbled onto this paper, High prevalence of vitamin D deficiency among pregnant women and their newborns in northern India. The authors chalk up the lack to their diet. I've already suggested nutrient deprivation with the switch to agriculture triggered the spread of the light skin variants in other contexts, and with the presence of the background condition of Vitamin D deficiency possibly driven by diet perhaps evolution is still going on in India?
Labels: Genetics
Thursday, September 13, 2007
Four Stone Hearth, the anthropology blog carnival, is over at John Hawks' place.
Labels: anthropology
Wednesday, September 12, 2007
This is a really strange story, Finland lures hi-end Indian tourists for winter experience:
Finland is wooing hi-end Indian travellers for a winter experience 'that rejuvenates the mind and body', includes a meeting with Santa Claus and a visit to the world's northernmost zoo in the Arctic Circle.` More seriously, India growth story charms Nokia-land: Though the current volume of trade between the two countries at 490 million euros hardly sounds happy, Finland -- from which the markets of Nordic and Baltic countries as well as Russia can be accessed -- is showcasing itself as the land of business opportunity. Or "India's gateway to Europe", as the Finns love to point out. Gateway to Europe? Perhaps I'm Anglo-centric, but such a gateway seems like a case of rear entry here.... Labels: Finn baiting
In the comments on a previous post about height of pretty boys, Jason suggested that they're so popular because they appeal to younger girls who value not-so-threatening guys more than do older women, and because their non-threateningness appeals to a given woman throughout the majority of her menstrual cycle, unlike the virile caveman-looking guys who only appeal to her during the narrow window of peak fertility. I think this view confuses pretty boys with safe, gentle father figures, and so do most studies that forces females to choose between safe, non-threatening guys and macho men. That's because there are not just two ideal types of guy -- the tough, polygynous alpha male vs. the supportive, monogamous dad -- but three, including the polygynous pretty boy / rockstar type.
This is a well established typology elsewhere in nature: the Common Side-blotched Lizard shows exactly these three types. The "sneaker" Yellow males, from afar, look just like females, allowing them to fly under the radar and copulate with numerous members of an Orange alpha-male's harem. The monogamous Blue mate-guarders have only one female to watch, and they cooperate with each other due to green beard effects (free text of the published article), so they can defend their female against sneakers. The three morphs play out a frequency-dependent game of rock-paper-scissors that cycles every six years. Right away, we've discovered one reason why so much genetic variation is maintained in traits relevant to sexual selection in humans, from personality traits to dancing ability to height -- there is likely no Evolutionarily Stable Strategy, since alpha-males can invade a population of demure good dads, fly-by-night types (pretty boys, artists, musicians, etc.) can invade an alpha-male population -- the latter might not worry about a pretty boy being around his girl since he might assume the guy was gay or otherwise unattractive to women -- but monogamous good dads can then clamp down on the fly-by-night debauchery by cooperating to erect morally upright social practices. There's probably some difference in the ecology of humans and the lizards that accounts for why the frequency of human morphs don't follow a clean, periodic pattern. We probably face greater temporal and spatial heterogeneity, so that there's rarely a winner-take-all moment when one morph displaces just about all members of the prevoius morph. So it's not like rock-paper-scissors where each strategy totally defeats exactly one other, and is totally defeated by exactly one other (separate from who it beats). Also, human females likely have much more choice than the lizard females, and could follow a mixed strategy (i.e., choose different types of males). Getting back to the datum that women find different types of guys more attractive when they're at their peak fertility during a menstrual cycle, we now see why pretty boys cluster more with alpha-males than good dads. Well, just behaviorally, babyfaced rockstars and actors are more likely to be polygynous than drab but devoted dads -- that's true for the lizards too. It's an error to suggest that pretty boys have a non-threatening appeal: if that were true, then they would appeal more to older females, who are more concerned about security than cutting loose and throwing caution to the winds. Also, which cohort of females is most likely to date drug dealers, gang members, or other dangerous males? Or to commit crimes and act dangerously and barbarically themselves? Not the older ones. And it's pretty clear that females who dig Johnny Depp or Jared Leto are not thinking what a great father he'd make. Rockstars and dreamy actors have legions of eager groupies throwing themselves at them -- hardly a long-term strategy. That's true even with non-famous rockstars, although the groupies number fewer: think of how many talentless bums with guitars you've seen get the girls. What is the more abstract trait that pretty boys and rockstars share with macho men, then? They're exciting, risky, volatile, and take-charge. So, the proper dichotomy is not "virile vs. wimpy" as has been supposed, but "exciting vs. drab," with the former having the two distinct sub-groups "macho man vs. pretty boy." Another way to see that this is the right dichotomy is to look around the world: wherever girls really dig macho men, they also dig the peacocky musician type too, finding safe guys a bit boring. And conversely, where devoted dads do the best, it's more difficult for macho men or in-town-for-a-day rockstars to make out like bandits. Bobbi Low has shown that pathogen stress is positively correlated with polygyny (free PDF). So whatever it is about high-pathogen-load areas that selects for greater polygynous behavior -- maximizing your offspring's genetic diversity to stay ahead of the pathogens? -- will result in an increase in both gorilla-like and peacock-like males, since they're two viable ways to pursue a polygynous mating strategy. In particular, this resolves the paradox of why men of West African descent tend to show higher levels of both the belligerent tough-guy, as well as the high-pitched singer who can dance better than most girls and has a penchant for dapper dress. Scandinavia and Northeast Asia, by contrast, show lower levels of badasses and show-offs but higher levels of good dads. That follows from the pathogen-load hypothesis, combined with the three-part, as opposed to two-part, typology of ideal male types. Labels: babes and hunks, Game Theory, maintenance of variation
Tuesday, September 11, 2007
Note: For those who need no explanation: Survey here, enter 55004 in Take A Survey box. Current results here.
Every now and then I do a "survey" on this website. Usually we get on the order of 300-500 responses. Generally we don't learn anything new (i.e., a disproportionate number of the readers tend to be young atheist libertarian males). But I've decided to try out a new hosted survey which might give us some correlation structure across the responses. There are 9 questions, and they shouldn't require much thought. Go here and enter survey number 55004 in the Take A Survey box. The link should open in a new window/tab, so don't worry about writing down the number, just look for the box at the right of the screen. You should be able to see the responses up to the moment, but I'll post the data breakdown across each question next weekend (e.g., atheist conditional upon being a libertarian, etc.). Thanks ahead! (This post will remain at the top of the page for several days) Labels: Blog
Monday, September 10, 2007
Chris reviews a study on the cognitive neuroscience of liberalism & conservatism (The LA Times has an article on the study). He's skeptical of the relevance and coherency of the findings. I would add that the heritability of political orientation is about 0.5, so I don't doubt that there's some innate predispositions which predispose individuals toward particular world views. Rather, I think this is analogous to genome surveys which can detect natural selection, but can't necessarily offer a plausible rationale for why selection occurred on a particular locus. Finally, I would add that my own hunch is that libertarians would probably be with the liberals here; because fundamentally there are some core axioms (individual self-actualization) and ends (a materialistic utilitarianism) which the Left and libertarians share despite the latter's traditional location on the Right.
Labels: Neuroscience
Our local unicorn rider TGGP has a blog up. Check it out! (TGGP has 'evangelized' GNXP posts and views on a wide variety of blogs so he deserves a front page link for sure) He has good taste, using the same them as Chet Snicker (whose blog has gone dead it seems....).
Labels: Blog
Sunday, September 09, 2007
Over at 2 Blowhards there's an interview with Greg Cochran. Greg is of course a "friend of the blog," and you mostly know him because of his work in the area of evolution. But he does have strong opinions on other topics, as you might have noticed if you subscribe to The American Conservative. Part II is coming up tomorrow.
Labels: Blog  The topic of facial attractiveness came up at Cognitive Daily, and it presents a good opportunity to contrast the two main approaches in psychology -- correlational and experimental. I'll start with an informal chat, and then proceed to look at a published study. Since the literature is vast, this will just touch on a few key points. And a warning to our mostly male readership: I'm only going to focus on what makes male faces attractive, both for "equal time" and because it's more mysterious. The topic of facial attractiveness came up at Cognitive Daily, and it presents a good opportunity to contrast the two main approaches in psychology -- correlational and experimental. I'll start with an informal chat, and then proceed to look at a published study. Since the literature is vast, this will just touch on a few key points. And a warning to our mostly male readership: I'm only going to focus on what makes male faces attractive, both for "equal time" and because it's more mysterious.Do girly eyes, lips, and skin make a guy less attractive? Hardly -- just look at any of those "teen hearthrob" magazines. In one response to a PNAS study, a photo of various dream guys features Billie Joe Armstrong next to the qualities "music" and "looks." What makes him look better than Bear Grylls and Kurt Vonnegut? Well, he has large girly lips and eyes, and tighter skin. This is typical of "pretty boys": other examples are Johnny Depp, Ryan Phillipe, and so on. However, the skeletal morphology (jaw, cheekbones, chin, brow) is masculine. It's only the non-boney parts that are girly. So, for guys, we've already found two principal components of facial attractiveness: a manly skull and girly soft parts that fill it out. But this brings up a very important point in asking such questions. That is, cognitive scientists often hew to the experimental approach -- let's keep two faces exactly the same, but change one feature, and see which is more attractive. This game of Mr. Potato Head purportedly avoids the entangled mess of confounding factors that would turn up in a correlational study, such as one using principal components. But there are good reasons to believe that there are non-trivial statistical interactions between facial features, so that isolating one and varying it misses the point: whether girly eyes are attractive depends on what the rest of the face looks like. It's just hard to judge the attractiveness of facial features out of context since facial perception is a pretty gestalt process. It's clear that part of the variation in facial appearance is due to genetic differences between individuals. Whatever these variational genes may be, their effects are pretty fundamental. There are probably significant epistatic (or gene-gene interaction) effects in skull morphology just because so many different parts have to coordinate their work to make the face look right. (Here is a study showing epistatic effects on the symmetry of mice teeth.) Throughout development, a single gene could have pleiotropic effects on various parts of the face, and ditto for a single circulating hormone. The point is, if we keep all of those the same and vary just one piece, we've lost the correlation structure. We could get wacko results for that reason alone. Imagine if a very ugly guy had his photo manipulated so that he had large girly eyes -- they would look very out of place, unsettling, perhaps jarring. We'd cringe from the bizarro effect alone. (For female faces, consider that very tight skin is attractive -- unless you take an old woman's head and give her a tight facelift, resulting in that extraterrestrial transvestite look.) In reality, though, girly eyes probably go along with other features that make them neutral or attractive. With that in mind, let's turn to a study on girly facial features in guys. Here is a free PDF, so if you comment, at least look at the pictures and read the graphs. What the experiments show is that, keeping everything else the same, increasing the luminance contrast between the (darker) eyes and lips vs. the (lighter) rest of the face made a female face increasingly more attractive, but a male face increasingly less attractive. The interpretation is that female-typical traits are attractive in females but ugly in males. If you look at the male pictures, though, it's clear why the feminized photo scored so low: he looks like a damned weirdo. Later in the paper, there are pictures of his entire head -- you can see that he has a very unattractive, schlubby male face. We react by cringing at his picture with high-contrast eyes and lips because it's so incongruous. Again, in real life, guys with more female-typical eyes and lips look like pretty boys, so it's not unsettling but rather attractive. I've already mentioned some mechanisitic reasons why that may be, but there could also be correlational selection on the skeletal and soft traits, or cross-assortative mating between males with manly skulls and females with doe eyes, pouty lips, and taut skin. As a reality check on the unsexiness of high-contrast eyes and lips for male faces, in the picture of Billie Joe Armstrong that The Intersection chose to showcase his good looks, he is wearing heavy mascara -- just as Johnny Depp did for the Pirates of the Caribbean movies. I'll bet that's also part of the hunk appeal when attractive football or baseball players are photographed with that black stuff under their eyes (functionally unnecessary for having your picture taken). Also, have a look at another study which created "average faces" from many real faces (these studies always show that the composite is most attractive). Their characteristics of beautiful faces shows a protypical sexy and ugly male face. First, note how similar the sexy non-skeletal features are for both sexes. It's hard to tell which face show a higher luminance contrast between the eyes and lips vs. rest of the face, since the sexy guy has darker skin. To me at least, the sexy guy has more pop-out-of-the-background eyes and lips, while the ugly guy has more uniformly drab features. But maybe a more sophisticated instrument than my eye will say that the sexy guy has lower-contrast features than the ugly guy. If so, the conclusion would be more believable since it did not come from a Mr. Potato Head experiment. So, on a constructive note, the way these studies of facial attractiveness should be done is to do something like PCA on a huge dataset of certified dreamy and drab guys. Just "by inspection," it's clear that "manly skull" and "girly soft features (eyes, lips, skin)" are two. Symmetry is another one, although as I mentioned at Cognitive Daily, symmetry is not heritable, so don't think that says anything about "good genes" sexual selection using "fitness indicators." Labels: babes and hunks, Psychology
Diet and the evolution of human amylase gene copy number variation:
...We found that copy number of the salivary amylase gene (AMY1) is correlated positively with salivary amylase protein level and that individuals from populations with high-starch diets have, on average, more AMY1 copies than those with traditionally low-starch diets. Comparisons with other loci in a subset of these populations suggest that the extent of AMY1 copy number differentiation is highly unusual. This example of positive selection on a copy number-variable gene is, to our knowledge, one of the first discovered in the human genome. Higher AMY1 copy numbers and protein levels probably improve the digestion of starchy foods and may buffer against the fitness-reducing effects of intestinal disease. From the digest in Nature News: When the researchers ventured beyond university campuses to sample populations in Africa, Asia, Europe and the Arctic, they noticed a trend. Cultures with diets that included high levels of starch tended to have more copies of the amylase gene than cultures that consumed few starches. This shouldn't be a big surprise. Some of justifications sound like those for lactase persistence, "The ability to digest starch may have had the added benefit of cutting down on diarrhoea." The rest of the commentary just writes itself, so I'll just let you go on with your internal monologue.... Page 2 of the supplemental PDF has some population level data (the N's are small of course for some of the groups). Related: Slow & diverse food. Labels: Genetics
Saturday, September 08, 2007
The New York Times has a story up about the boys who have to be expelled from the Fundamentalist Church of Jesus Christ of Latter Day Saints of Warren Jeffs. This group practices obligate polygyny (you have to have at least three wives to make it to heaven) so teenage boys are thrown out of the community with the merest pretense to maintain a suitable sex ratio. Because they have led regimented lives and lack much formal education the transition to "normalcy" is often difficult. A story at CNN emphasizes the large role that alcohol and drugs end up playing in their lives after expulsion; what was forbidden now becomes the ends of existence.
Obviously a fundamentalist Mormon sect is atypical in many ways. Nevertheless, I do think that it is simply an exaggeration of cultural forms which were and are quite normal across much of the world. The values of fundamentalist Mormons are not so opaque to someone from a 'traditional' cultural perspective. Here you have a society where a group of older men have fiat power over the most basic and critical aspects of the lives of their flock. There are fierce social and psychological controls at work which serve as tools for Warren Jeffs and his acolytes. The boys profiled note that they were terrified that they were going to hell if they disobeyed the leaders of their church. In terms of individual worth the only figures who have a modicum of autonomy are the powerful old men who control the levers of the culture. Most individuals are boxed in by birth and circumstance, they have minimal choice in terms of alternatives options, their social networks are within the same group so the norms of authority and control are reinforced and replicated. These oppressive cultural systems are certainly at variance with the liberty and autonomy which are held in such esteem in the modern West. But they "work," as can be attested by their pervasiveness. I believe that the past 10,000 years has been the story of the rise of patrilineages, cabals of powerful men who monopolize and control the surplus of any given society. Though rarely as totalitarian as Warren Jeffs and his cronies, they regulated the lives of their close relations and other figures of note to maximize the status of their lineage. Even if the peasantry were not impacted by the taboos and incentives which pervaded the lives of the elite because of practical constraints, they certainly knew what the "right" way to live life was. Modernization and increasing affluence often lead to emulation of traditional elites so that the median "best practices" in a given society become more regressive from a Western angle as it becomes more "advanced." This trend of increased inequality and the monopolization of economic surplus by an oligarchy has only been reversed over the past few centuries in the West. Concomitantly we have seen the decreased role for the religious institutions which offered an imprimatur of sacredness to the political and social systems of control. Though individuals may still be religious, they pick and choose an institutional affiliation and no longer fear the synergistic coercive power of church and state. Liberty is an idea we hold dear, but it is also an economic reality insofar as the average man or woman in the West now lives far above basic subsistence and can choose from a wide array of luxury goods to satisfy their wants and needs. Social systems which arose during the agricultural interlude, when the typical human lived on the margins of subsistence through perpetual back-breaking labor and a small leisured elite warred and philosophized, still remain with us as ghosts from a bygone age. The rate of economic and social growth, and the disjointed nature of the process, means that the past and the present and the future all face each other every day. In the modern West one of the major manifestations of this trend is the experience of 1st generation immigrants and their offspring. The parents grew up in a subsistence society, often buttressed by familial obligations and expectations. The children socialize in a consumer world where choice is a given. A father kills his daughter because she has entered into a sexual relationship with an outsider before marriage and without his permission. These are the things that happen when the past faces the present.
Friday, September 07, 2007
Science needs the check of experiment and observation because we aren't smart enough to generate very long sequences of inferences from first principles without walking off into fantasy land. For example, check out this exchange between Freeman Dyson and Richard Dawkins. Dyson is a physicist who has made some serious contributions to our body of knowledge. He is a realized genius; the promise of his brilliance was kept. Richard Dawkins on the other hand has made his mark as a popularizer of science. With a second class degree from Oxford, he has admitted difficulties with differential calculus (see A Reason for Everything). Dawkins is a bright enough fellow when measured against the mean, but in terms of g I have no doubt that Dyson stands head and shoulders above him by ~1.5-2 standard deviations. Nevertheless, Dyson says the following:
First response. What I wrote is not a howler and Dawkins is wrong. Species once established evolve very little, and the big steps in evolution mostly occur at speciation events when new species appear with new adaptations. The reason for this is that the rate of evolution of a population is roughly proportional to the inverse square root of the population size. So big steps are most likely when populations are small, giving rise to the ''punctuated equilibrium'' that is seen in the fossil record. The competition is between the new species with a small population adapting fast to new conditions and the old species with a big population adapting slowly. I don't do the "fisking" thing, and in this case it is too easy. I just want to fix onto his formal allusion; Dyson is basically conflating random genetic drift with evolution itself. He should look up Neutral Theory and its prediction of a constant rate of substitution. And then there is Fisher's Fundamental Theorem of Natural Selection. But even if you reject these models, extrapolate from the assertion he makes to the world around you: do species with the smallest effective populations evolve the fastest??? To think with speed and clarity is critical in modeling the world around us. But to know facts is also important. Freeman Dyson has a excellent inferential mental engine, but he obviously isn't able to derive the insights of evolutionary genetics from first principles on the fly. He should read a book, otherwise he'll have to deal with being schooled by minds of far lesser rate. Note: Dyson reports that his response to Dawkins' critique was presented verbally at John Brockman's farm in the presence of biologists. That would be George Church & Craig Venter at the least. Perhaps I'm a retard from bizarro world and everything I've learned is turned upside down, but I'm a bit mystified as to why Dyson wasn't immediately corrected. OK, actually I'm not. It seems likely that Dyson was around molecular people would couldn't respond with a sentence as to why the rate of evolution isn't dependent on population size in the way he believes. Labels: Genetics
Published today in PNAS is a paper by Peter Todd and colleagues on mate choice in humans. Of course, everybody and their mother has already commented on it, based on a press release, or a Fox News article, or something (science bloggers: disdainful of science press coverage in their own field, yet unthinkingly accepting of it in others?). It's always interesting, though, when some paper of possibly general interest comes out, to compare the reactions of people familiar with the line of research with those not. In this case, compare the reactions of Kate at The Anterior Commisure or the Mungers at Cognitive Daily, two blogs which touch on cognitive science and psychology, with the reactions of Sheril at The Intersection (a marine biologist) or Rob Knop at Galactic Interactions (a physicist). The former seem to recognize that they can't say much without reading the study, and use it as a jumping-off point to talk about the psychology of attraction in general, while the latter seem to have no trouble immediately identifying a fatal flaw in the researchers' assumptions. Hm. Something to think about (or don't think about it. If any scientist were to publicly criticize my research methods based on a Fox News article, I'm going to go out on a limb and say I'd be pretty damn pissed).
Anyways, now that the study is out, it turns out everybody was focusing on an entirely peripheral point in the paper. Yes, women are more "choosy" than men, and yes, money and status matter to women, and yes, looks matter to men, but that's not news. As Jason Malloy points out, if that's all this paper were to show, it wouldn't be in PNAS. I'm going to quote him in full (unless he objects): This dataset looks laughably amateur when there are other recently analyzed speed-dating (and related) datasets with literally 1000s of people. Here is a speed-dating study from last year (PDF):So this study isn't breaking any new ground in that regard (which seems to be the one people have focused on). Rather, the part that seemed novel to me (though I think I may have heard of research like this before) was to ask people beforehand what they're looking for in a partner, then compare that to their actual behavior. It's actually kind of amusing: Table 3 depicts the correlations (separated by sex) between choice scores and stated preferences. The correlations for women are generally low for all domains except physical appearance and overall preferences (i.e., "ideal mate value" compared with "selected mate value"). Notably, men show a consistently negative relationship between stated preferences and chosen attributes. These counterintuitive correlations are significant for physical appearance and healthiness and marginally significant for overall preferences. Conversely, the results revealed a positive (although not significant) correlation between men's stated attractiveness preferences and the mean observer-rated attractiveness of their chosen women. As a whole, these findings indicate that there is a rather poor match between our sample's verbally stated preferences for mate traits and the preferences they expressed through their actual mate choicesThat is, people essentially lie to themselves (or perhaps only to observers) about what they're looking for in a partner. Some commenters have fixated on the role of culture in preferences as something not accounted for by this study, but the data seem to suggest that, while it's not culturally acceptable to say that you're judging someone by their looks, well, that's what ends up happening anyways. Note to commenters: please do not tell me how you met your wife/girlfriend and how your personal experience differs with the conclusions here, or about your successes/failures in online dating. I don't care. Labels: Cognitive Science
In this invited address to the American Psychological Association, Roy Baumeister has quite a lot of fun with his topic: "Is there anything good about men?" His major themes will be familiar to GNXP regulars--Larry Summers, the high male variance of IQ, genetic and cultural explanations, a rejection of the culture war and a call for science--but it's a tale well told. A typical quote:
[M]en really are better AND worse than women. Great to see the APA having this kind of discussion. (Hat tip: Bryan Caplan of Econlog.)  Over 40 years ago the physical anthropologist C.S. Coon wrote The Origin of Races. Along with The Living Races of Man this book is an excellent source for on all sorts of obscure and hard to find anthropometric data. As Peter Frost has noted it can be rather difficult to find information on the distribution of the most mundane of human characteristics because of the shift away from the descriptive physical anthropology. If you want frequencies on blue eyes in Sweden, your data set is likely to predate World War II. Over 40 years ago the physical anthropologist C.S. Coon wrote The Origin of Races. Along with The Living Races of Man this book is an excellent source for on all sorts of obscure and hard to find anthropometric data. As Peter Frost has noted it can be rather difficult to find information on the distribution of the most mundane of human characteristics because of the shift away from the descriptive physical anthropology. If you want frequencies on blue eyes in Sweden, your data set is likely to predate World War II.That being said, the model posited in The Origin of Races is false, Coon hypothesized that six primary races had their origins in independent transitions to sapiency by their hominid precursors. In this model the seeds for racial difference existed on the order of tens of millions of years before the present. Though a great collector of data and a vivid storyteller, like most of the physical anthropologists of the first half of the 20th century Coon's scientific methodology was heavily intuitive and seemed to be guided mostly by gestalt impression. The subsequent genetic revolution, starting with the successful challenge by the proponents of the molecular clock to the older paleontological model of the origin of hominids which assumed a very early separation from the great apes, and ending with the ascendance of Out-of-Africa over a Multiregional conception of modern human origins, made the older anthropological taxonomy look amateurish. L.L. Cavalli-Sforza's The History and Geography of Human Genes rendered much of the more imaginative anthropological literature on racial history a historical footnote. I've avoided terms like Mongoloid and Caucasoid because of their associations with an older anthropological taxonomical tradition which seemed basically irrelevant in terms of the theoretical framework. Even the early serological work on the Ainu of Japan seemed to show that this putatively Caucasoid population, as determined by older anthropometric methods and description, was more closely related by descent to the populations of East Asia than to Western Eurasians. Analysis of the Indian subcontinent seemed to show that there was more genetic distance between these peoples and those of the Middle East & Europe than some of the older models had projected. I did not see great need to look to the older literature for pointers or guides when genetic markers could tell the full tale. But lately I've been reconsidering. Though the racial migrations posited by the physical anthropologists of the early 20th century were generally more shaped by their cultural context and imagination than reality, the anthropometric data they collected wasn't manufactured out of whole cloth. The description tracked a real pattern in the data. Though the hypotheses were not very informed by the latest in evolutionary and genetic theory, they were not uninformed by fact. Lately I've been posting a lot about lactase persistence and skin color. These two genetic characteristics have come a long way in terms of their understanding over the past few years. At my other blog I posted yesterday about a study which studied the skin color variation in South Asians. The SNP of SLC24A5 which is fixed in Europeans and not present in Africans and East Asians, seems to exhibit high penetration within South Asia. In fact, it explains about the same proportion of the skin color difference between the lightest and darkest quintile of South Asians as it does in relation to the complexions of Europeans and Africans. Lactase persistence also exhibits a similar pattern, the same allele seems to have swept from the Atlantic to the Bay of Bengal. Its penetration into Sub-Saharan Africa is patchier, and it seems not to have any discernible impact on East Asia. In The Real Eve, a survey of the literature on neutral genetic markers as proxies for ancestry, Steve Oppenheimer asserted that the basic population groups we see around us today were established and in place by the end of the last Ice Age. In other words, most of the ancestors of people in East Asia, the Middle East, South Asia, Europe and Africa were on those continents 10,000 years ago. Of course there have been changes within the continents, the expansion of the Han within the last 3,000 years in China or the Bantu expansion in Africa are two examples. Additionally, there have been genetic overlays upon the bedrock, for example, the injection of African and Arabian female and male lineages respectively throughout what has become the Arab world over the last 1,500 years. The signature of a Neolithic demic diffusion into Europe from the eastern shores of the Mediterranean starting about 10,000 years ago. Evidence in South Asia of population movements from West and Central Asia from antiquity down to the Islamic period. Nevertheless, in narrative generated by the neutral markers is that the races of man were extant more or less 10,000 years ago and only the margins and details have been affected by subsequent migrations. I think this is wrong, and Oppenheimer in his chapter on East Asia supplies a clue to why this story isn't complete: he notes that the classical East Asian physical type, that is, Mongoloid, seems to emerge very recently. One could posit that this and artifact due to the paucity of fossil remains in this region for anatomically modern humans. But no, I think the answer is that the Mongoloid physical type emerged within the last 10,000 years due to recent human evolution! We also know from the data that the classical Northern European with fair hair, blue eyes and a taste for milk is also a recent evolutionary development, within the last 10,000 years. In Africa malaria probably resulted in some of the highest selection coefficients known to man, all within the last 5,000 years. In South Asia we know that lactase persistence and lighter skin are due to recent evolution, and likely both are exogenous. In fact, the allele is identitical by descent with that which is common in the Middle East and Europe. And this last fact brings me to another observation: the patterns of cultural diffusion which seem to characterize the pre-modern world might very well serve as a map for the sweeping of mutants of large effect across Eurasia over the past 10,000 years. The genetic architecture for light skin color are radically different in East Asia as opposed to Europe, the Middle East and South Asia. Similarly, the alleles for lactase persistence that are West Eurasian are found in the same broad swath of land where SLC24A5 seems to have made an impact: from Europe down into North Africa across the Middle East and South Asia. This area is also the classical home of the Caucasoid race, which Coon characterized by its lack of specialized features vis-a-vis Africans and Mongoloids. I am struck by the correspondence here with a particular cultural pattern that reoccurs: memes which originate along the fringe of Eurasia east from India and west to Spain as well as at the nexus with Africa seem to stop at the Sahara and the Himalaya. Consider the scripts dominant from India to Spain, they derive from Aramaic. In contrast, Chinese writing is based on a different model. Consider the Indo-European and Afro-Asiatic languages which span such broad expanses, from the Atlantic to the Bay of Bengal, from the Niger river to borders of Anatolia. Consider that the One True God is worshipped from Europe to Bengal. In The Human Web the historian William H. McNeil describes the slowly growing networks of information which spread across the globe over the past 3,000 years. He posits the origination of hearths, proto-civilizations, which slowly became entangled in a dense network of trade and political unification. One of the earliest major dynamics which persisted to the relatively recent past was the separation of East Asia from Western Eurasia. Though there were contacts and diffusions, the three major cultural hearths, the West (Europe & the Middle East inclusive), India and China did not have symmetrical relationships. The West and India, though alien and viewing each other as exotics, did have a non-trivial amount of trade and cultural exchange. As early as the Persian Wars soldiers recruited in the Indian provinces could be found involved in European conflicts, while Indian philosophy seems to have had an indirect and diffuse influence upon later Greek philosophy (by which I mean Neo-Platonism and such). Small communities of Christians & Jews and Roman coins in southern India, or the adventuring of Central Asians and Africans in armies of Muslim sultans, attest to South Asia's connections to the West. Even as far back as the Sumerians there was most certainly contact between India and the Middle East (references to Meluhha and trade items found in Harrapa is evidence of this). In contrast, ancient China was a relatively isolated land encircled by barbarians. Granted, some cultural ideas seem to have percolated from the West to the East, and the presence of Christians, Jews and Muslims in China from an early period attest to the more vigorous contact of the last 2,000 years. Nevertheless, the extinction of both the early Jewish and Christian communities attests to the relative isolation from the wider world which still characterized China until the early modern Age of Exploration. And so it might be with genes. Though there was certainly some traffic between the antipodes of Eurasia, the migration was low enough that independent mutations with similar phenotypic effects seem to have arisen in the different domains. With the rise of agricultural society, enormous populations, increased rate of cultural evolution, I suspect that biological evolution was also cranked up through the simple change of prosaic population genetic parameters (more mutants, more long distance migration, etc.). Alleles of large effect could have swept repeatedly across distinct and long separate populations and bound them together as functional clusters. At the end of the last Ice Age the whole region from the Atlantic to South Asia was characterized by a sparse population just reemerging from their refugia. Long isolated from each other by the Last Glacial Maximum these populations were genetically quite distinct, especially between South Asia and Europe & the Middle East. But just as the rise of long distance trade spread ideas across these disparate zones, so genetic evolution swept along the routes of migration. A group like the Indo-Europeans may be only a small proportion of the ancestry of modern Persians, Indians, Germans and Russians, but they might have been significant in spreading genes of great impact across this broad zone, generating surface commonalities which contradict the deep time cleavages wrought by the isolation of the Ice Age. What I am positing is an inversion of the dynamic which Henry Harpending brought to my attention years ago, he pointed out that some populations exhibit similarity of ancestry but sharp differences of phenotype. Harpending's model was that social selection on particular loci could perpetuate physical differences between groups which intermarried and so equilibrated on most markers. In contrast, the model here that I am proposing is that the differences of ancestry may belie the common ground on major functional loci across several population clusters. And similarly, adaptive evolution may result in divergences in appearance between groups with relatively recent common ancestry, as seems the case in relation to Ainus and other East Asians. All in all, it is a complex & baroque picture, but one which I believe will exhibit interesting systematic patterns. Presenting this in a pithy, precise and accurate manner to the public, well, that's a different story.... Labels: Genetics, human biodiversity
Virpi Lummaa has a paper up at PLOS One, Natural Selection on Female Life-History Traits in Relation to Socio-Economic Class in Pre-Industrial Human Populations:
...We found the highest opportunity for total selection and the strongest selection on earlier age at first reproduction in women of the poorest wealth class, whereas selection favoured older age at reproductive cessation in mothers of the wealthier classes. We also found clear differences in female life-history traits across wealth classes: the poorest women had the lowest age-specific survival throughout their lives, they started reproduction later, delivered fewer offspring during their lifetime, ceased reproduction younger, had poorer offspring survival to adulthood and, hence, had lower fitness compared to the wealthier women. Our results show that the amount of wealth affected the selection pressure on female life-history in a pre-industrial human population. Lummaa's data is from the 18th and 19th century in Finland, but in many ways it is generalizable. In post-demographic transition societies we are faced with the fact that the lower social classes tend to be more fecund, but for most of human history this was not an operative dynamic. I believe some of the resistance to Greg Clark's contention that the wealthy gentry were the predominant ancestors of the modern British population is simply due to its relative counter-intuitiveness to the modern middle class, who simply can't believe that anyone responsible would breed to their maximal reproductive capacity. Before Chris Surridge starts riding me, please be aware you can leave comments over at PLOS One! Pettay JE, Helle S, Jokela J, Lummaa V (2007) Natural Selection on Female Life-History Traits in Relation to Socio-Economic Class in Pre-Industrial Human Populations. PLoS ONE 2(7): e606. doi:10.1371/journal.pone.0000606 Labels: Finn baiting, Genetics, History
Several months ago I promised a series of posts on the work of Sewall Wright. This has been delayed for various reasons, including some time spent on this.
Another problem is that understanding Wright's work requires some knowledge of the theory of correlation and regression. Wright was accustomed to express his theories in terms of correlation, even in cases where other methods would now be preferred. For example, Malecot's interpretation of kinship in terms of identity by descent has completely replaced Wright's correlational approach. The problem is that I don't want to presuppose any great knowledge of correlation and regression by the reader. Statisticians may take these things for granted, but it is salutary to note that George Price, when he began his work on altruism, 'didn't know a covariance from a coconut'. Unfortunately I don't know of a good online source containing everything the reader needs to know as background to Wright. The various Wiki articles on correlation seem too mathematically sophisticated for the general reader. Nor do I know of any modern statistical textbook that I can recommend, as I find that in general they are either too advanced or too elementary. For my own purposes I prefer some classic older works. My 'bible' for statistics is George Udny Yule's Introduction to the Theory of Statistics. (From the 11th edition onwards this was co-authored by Maurice Kendall. I have the 14th edition, 1950.) Quinn McNemar's Psychological Statistics (2nd edition, 1955) is also very good. J. P. Guilford's Fundamental Statistics in Psychology and Education (2nd edn., 1950) has a good text, but seldom gives proofs of formulae. For the historical aspects of correlation and regression I particularly recommend Stephen Stigler's The History of Statistics: The Measurement of Uncertainty before 1900 (1986) and Theodore Porter's The Rise of Statistical Thinking 1820-1900 (1986). It is also still worthwhile to look at some of Francis Galton's original papers on correlation and regression, which are all available here. For general readers the best is probably his 1890 article on 'Kinship and Correlation'. From time to time I have made notes of my own on various aspects of correlation and regression, largely to ensure that I do not forget things I have worked out for myself. It occurred to me that if I strung these notes together with some linking commentary, they might provide the necessary background for my posts on Wright. This has proved harder than I expected. It is really difficult to treat these subjects in a way that is clear, concise, self-contained, unambiguous, and not too mathematically complicated. It is all-too-likely that some errors have crept in, so please let me know if you spot any. I have divided the notes into three parts. The first part contains preliminaries about notation, etc, and introduces the concepts and main properties of bivariate (2-variable) correlation and regression. Part 2 will prove some important theorems and discuss some problems of interpretation. Part 3 will cover the basics of correlation and regression for more than two variables. Even divided into these chunks the notes are long, and I do not imagine that anyone will want to read them all in one go. Hopefully they will be useful to people searching the web on these subjects. I will link back to them if and when I get round to the notes on Wright. So here is Part 1: [Added on Sunday 9 September] I have gone to some trouble to represent standard mathematical symbols in this blog publishing system, in such a way that they are readable by all common browsers. I thought I had succeeded, and it all looked OK when I posted it. But as of now (9.00 GMT) some nonsense symbols are appearing in my own browser! This may be a temporary problem (the publishing system sometimes goes haywire) but if not, I will try and fix it.] [Added again: I don't know what the problem is, but the symbols are still unreadable in my browser, even though a short test post worked OK. So in case the problem continues, I have added a 'plain text' version which does not use math symbols. If you can't read the original version properly, scroll down to 'Version 2 (plain text)'. I have also taken the opportunity to add an explanatory remark about 'dependent' and 'independent' variables.] [Added on Tuesday: I have now deleted the original version of the Notes, as it seems that most people could not read the math symbols, and it was just taking up space. I take this opportunity to emphasise that the Notes are not aimed at expert statisticians, and do not claim to deal with the most up-to-date issues in the theory of regression and correlation. On the other hand, I do believe that the issues discussed by such founders of statistics as Francis Galton, Karl Pearson, Udny Yule, R. A. Fisher, and Sewall Wright (whose statistical work has been somewhat neglected) are still interesting and important, and that modern students neglect the 'old masters' at their peril.] Preliminaries Unless otherwise stated, these notes deal only with the linear regression and correlation of two variables. Questions of sampling and measurement error will not be covered. I assume that there are two sets of observations or measurements, represented by the variables x and y, with N items in each set, paired with each other in some way. In dealing with the correlation or regression between two sets of data, we must have some particular pairing in mind: obviously different pairings could produce different results. There is no limit on the kind of relationships that can be taken into account, provided there is a one-to-one correspondence between the items in the two sets. In some cases the same observation may be counted more than once: e.g. if we want to correlate the height of fathers and sons, some fathers may have more than one son, in which case the father's height may be counted as a separate item in relation to each son. It is assumed that all items have a numerical value. Usually this will be the result of some process of counting, measurement, or rank-ordering, but numbers can also be assigned to qualitative characters according to some arbitrary rule. For example, in order to calculate a correlation between siblings with respect to eye colour, blue eyes might be given the value 1 and brown eyes the value 2, or vice versa. In dealing with the theory of correlation and regression it is often convenient to express quantities in each set of values as deviations above or below the mean of the set. So, for example, if the x variable denotes measurements of human heights, and the mean height in the population is 68 inches, then a height of 65 inches can be represented by a deviation value of -3, and a height of 70 inches by a deviation value of 2. In reading any text on correlation or regression, it is important to note whether the author uses raw values or deviation values in his formulae. I will often use deviation values, as this results in simpler algebraic expressions. Notation This version of the notes uses only non-mathematical typography. Large S will represent the sum of a set of quantities. Small s will represent the standard deviation of a set of quantities. V will represent the variance (the square of the standard deviation). ^2 will represent the square of a quantity. # will represent the square root of a quantity. Subscripts will be represented by a low-level dash, e.g. x_1 would represent x with the subscript 1. The sum of each x value multiplied by the corresponding y value will be denoted by Sxy. The sum of each x value plus the corresponding y value will be denoted by S(x + y). The mean of the raw x values (their sum divided by N) will be denoted by M_x, and the mean of the raw y values by M_y. The deviation values of x and y are then (x - M_x) and (y - M_y) respectively. The following points follow from these definitions and the standard rules of algebra: (a) S(x + y) = Sx + Sy (b) Sxy is not in general the same as SxSy (the sum of all x values multiplied by the sum of all y values). (c) Sx^2 (the sum of the x values individually squared) is not in general the same as (Sx)^2 (the square of the sum of the x values). (d) Where 'a' is a constant, S(xa) = aSx. (e) S(x + a) = Sx + Na (since the constant enters into the sum N times, once for each value of x.) (f) S[(x + a)(y + b)] = Sxy + bSx + aSy + Nab. Here the scope of the summation sign is the entire expression in square brackets. The intended interpretation is that each term (x + a) is to be multiplied by the corresponding (y + b), where a and b are constants. Note that the resulting sum includes the product ab N times, once for each pair of x and y values. (g) S(x + a)^2 = Sx^2 + 2aSx + Na^2 (h) M_x = Sx/N, and M_y = Sy/N, where x and y represent raw values. (i) It follows from (h) that the deviation values of x can be expressed in the form (x - Sx/N). The sum of the deviations is therefore S(x - Sx/N). But by point (e) this sum is equivalent to Sx - NSx/N = 0. Likewise for y. Therefore if we use x and y to represent deviation values, instead of raw values, then Sx = Sy = 0. The variance of the x values will be denoted by Vx, and of the y values by Vy. By the definition of variance Vx = [S(x - M_x)^2]/N, where x represents raw values. If x and y are already expressed as deviation values, Vx = (Sx^2)/N and Vy = (Sy^2)/N. It follows that with deviation values NVx = Sx^2 and NVy = Sy^2. The standard deviation of x will be denoted by sx, and of y by sy. By definition sx is #Vx, and sy is #Vy. (Strictly, though not all texts are explicit on this point, the standard deviation is the positive square root of the variance, otherwise there would be an ambiguity of sign in many formulae.) The meaning of regression and correlation The usual explanation of regression and correlation is something like this: Regression provides a method of estimating or predicting the value of one variable given the corresponding value of the other variable. The latter variable is multiplied by a coefficient of regression to contribute to the best estimate of the first variable. [Added: The variable whose value we wish to estimate is usually called the dependent variable, and the other the independent variable, but these terms do not imply a direct causal relationship between them, or that if there is a casual relationship the causation runs from the independent to the dependent variable. 'Dependent' is merely a conventional term to designate the term whose value we want to estimate.] If we denote the coefficient of regression by b, the equation x = a + by (where a is a constant, which may be positive, negative, or zero) provides the best estimate of x given the corresponding value of y (the regression of x on y). The term 'regression' itself is an unfortunate historical accident arising from the specific biological context in which the concept was originally formulated by Francis Galton. Alternative terms have sometimes been suggested, but did not catch on. Of course, we do not always literally want to estimate or predict the value of a variable. The value may already be known, in which case prediction would be unnecessary, or easily measured, in which case a mere estimate would be a poor substitute. The use of regression is more often in connection with hypotheses. We may want to formulate a hypothesis about the general relationship between two variables, or we may already have such a hypothesis and want to test it. Calculating a regression coefficient may suggest such a hypothesis, or put an existing one to the test. The regression coefficient of x on y need not be the same as the regression coefficient of y on x. Regression is not a symmetrical relation. Correlation, on the other hand, is a measure of the closeness of the relationship between the x and y values. Correlation is symmetrical, since x is as closely related to y as y is to x. Another way of putting it is that regression gives the best estimate of one variable given the other, while correlation measures how good the estimate is. (This is not to be confused with the question how reliable it is, in the sense of how much it varies when different samples are taken from the same population. This is a matter for the theory of sampling, which will not be dealt with here.) The closer the relationship, as measured by the correlation coefficient, the better the estimate. A positive correlation implies that high values of one variable tend to go together with high values of the other, while a negative correlation implies that high values of one variable tend to go together with low values of the other. A zero or near-zero correlation implies that the relationship between the variables is no closer than would be expected by chance. The Pearson Formulae The standard formulae for linear regression and correlation were devised in the 1890s by Karl Pearson (partly anticipated by Francis Ysidro Edgeworth). They are often known as the Pearson product-moment coefficients. (Other formulae, such as the intraclass correlation coefficient, the tetrachoric correlation coefficient, or rank order correlations, may be used for certain special purposes. In general these are modifications of the Pearson formulae rather than fundamentally different approaches.) A simplified derivation of the formulae was introduced by George Udny Yule. Using the notation explained above, the Pearson coefficient of regression of x on y can be expressed as Sxy/Sy^2, or equivalently Sxy/NVy, where the x's and y's are deviation values . The 'best estimate' for the value of x given the corresponding value of y is therefore x = a + (Sxy/Sy^2)y. (In fact, when deviation values are used, a = 0.) The coefficient of regression of y on x can be expressed as Sxy/Sx^2, or equivalently as Sxy/NVx. It will be noted that both regression coefficients contain the term Sxy/N. This is known as the covariance of x and y, or cov_xy. The regression coefficients can therefore also be expressed as cov_xy/Vy and cov_xy/Vx. The coefficient of correlation between x and y is Sxy/Nsx.sy, or equivalently cov_xy/sx.sy, where x and y are deviation values. The correlation coefficient is traditionally designated by the letter r, and the correlation between x and y as r_xy. Note that Sxy = r_xyNsx.sy. The use of r (and not c) for the correlation coefficient is another historical accident. It originally stood for 'reversion' in an 1877 paper by Galton. In 1885 Galton adopted the term 'regression', and kept the abbreviation r, even when he later subsumed his concept of regression in the broader concept of correlation (see further below). Karl Pearson and other statisticians continued to use r for correlation, and the usage is too deeply rooted to change. There does not seem to be any universal abbreviation for the coefficients of regression. Small r is pre-empted for the correlation coefficient, and large R is often used for another purpose (the multiple correlation coefficient). Some authors use Reg. or reg. to indicate regression, but this seems clumsy. The letters B, b, or beta are sometimes used for regression coefficients, and I will use b. Since regression is not in general symmetrical, it is necessary to distinguish between b_xy and b_yx, where b_xy is the coefficient of the regression of x on y, and b_yx the coefficient of the regression of y on x. There is a close mathematical relationship among the coefficients of correlation and regression, which all contain the term cov_xy, and can be converted into each other by multiplying or dividing by sx and sy. For example, the coefficient of the regression of x on y, b_xy = Sxy/NVy, can be expressed as (r_xy)sx/sy, and the coefficient of the regression of y on x, b_yx = Sxy/NVx, as (r_xy)sy/sx. It follows that b_xy = b_yxVx/Vy. The correlation coefficient r_xy is the 'mean proportional' between the regression coefficients, #(b_xy)(b_yx). The regression and correlation coefficients can be expressed in a variety of other equivalent formulae. Some authors use expressions with raw values of x and y, rather than deviation values, in which case the correlation coefficient takes the form S(x - M_x)(y - M_y)/Nsx.sy. It can be shown that S(x - M_x)(y - M_y)/Nsx.sy = (Sxy - NM_x.M_y)/Nsx.sy so this formula is also often used. Another equivalent formula for raw values is (NSxy - SxSy)/#[NSx^2 - (Sx)^2]#[NSy^2 - (Sy)^2]. Some authors (especially on psychometrics) also assume that all quantities are expressed with their own standard deviation as the unit of measurement, in which case sx = sy = 1, and the coefficients of correlation and regression all reduce to cov_xy. Formulae are also sometimes modified to allow for sampling error. The choice of the formula to use depends on the purpose. For theoretical purposes it is generally simplest to use formulae with deviation values. For example, if we square the correlation coefficient for deviation values, Sxy/Nsx.sy, the numerator of r^2 is (Sxy)^2, whereas if we squared it in the form for raw values, S(x - M_x)(y - M_y)/Nsx.sy, the numerator in its simplest expression would be (Sxy)^2 - 2(Sxy)NM_x.M_y + N^2M^2_x.M^2_y. Further work involving r^2 in this form could get very messy, e.g. if several such items have to be multiplied together. If on the other hand we needed to calculate the actual value of a coefficient from empirical data, one of the raw-value formulae would be more convenient. But the need for this now seldom arises, as correlation and regression coefficients can be calculated from raw data even by modestly priced pocket calculators. What is a 'best estimate'? As noted above, the regression of x on y is usually described as producing the 'best' estimate of x given y. But in what sense is it the best? The texts usually just say that it is the estimate given by the method of least squares, that is, the estimate that minimises the sum of the squares of the differences between the estimated values and the observed values, or the 'errors of estimation'. The criterion of 'least squares' was taken over by Pearson and Yule from the theory of errors, as used in astronomy, geodesy, etc, for determining the best estimate for a physical value (e.g. the true position of a star) given a number of imperfect observations. But why is this the best estimate? There are some good practical reasons for using the method of least squares. An estimate based on least squares is unbiased, in the sense that it has no systematic tendency to over- or under-estimate the true value, and it makes use of all available information (unlike, say, an estimate using median or modal values). It is also stable, in the sense that a small change in the observations does not produce a large change in the estimate. The method has various more technical advantages. But beyond this, many 19th century mathematicians regarded it as giving the most probable value of the unknown true quantity. This requires assumptions to be made about the distribution of prior probabilities. If it can be assumed that all possible values of the true quantity are equally probable a priori, then the method of least squares gives the most probable true value after taking account of the observations. [Note 1] But the assumption of equal prior probabilities would not nowadays be generally accepted as valid, in the absence of any empirical evidence about the distribution of probabilities. And even if it were, it is not clear that a method devised for the estimation of physical quantities, which have a single 'true' value, can legitimately be used to estimate a variable trait of a population. However, the method seldom gives intuitively implausible results. One advantage is that if we want to make a single estimate for any set of numbers, the estimate given by the method of least squares is simply their mean. Suppose that the x's designate the raw values of a set of N numbers. If we take the mean value M_x as an 'estimate' of the x's, the sum of squares of the 'errors of estimation' is then S(x - M_x)^2 = Sx^2 - 2Sx.M_x + NM^2_x = Sx^2 - NM^2_x. For any other value of the estimate, greater or less than the mean by an amount d, it will be found after a bit of algebra that the sum of squares of the 'errors' equals Sx^2 - NM^2_x + Nd^2, which is greater than the earlier estimate by Nd^2. But Nd^2 is necessarily positive, for any non-zero value of d, so the sum of squares of the errors is greater than when the estimate is the mean. The mean is therefore the 'least squares' estimate. The main practical weakness of the least squares method is that it may give too much weight to 'outliers' - freak extreme values which add disproportionately to the sum of squares. In the case of a regression equation, we do not want a single estimate for the whole set of observations, but the best estimate of the dependent variable for the corresponding value of the independent variable. If there are several values of the dependent variable corresponding to a narrow range of the independent variable, then we can plausibly regard the mean of those values as the best estimate associated with that particular range. The regression equation based on the Pearson formula does in fact give a close approximation to that mean value, provided samples are reasonably large, and the distribution of both variables is approximately normal. It might be supposed that the 'best' estimate would be the one that minimises the absolute size of the errors (disregarding sign), rather than the squares of the errors. However, the absolute size of the errors is usually more difficult to calculate, and it can lead to intuitively odd results. [Note 1] 'Least squares' therefore prevails, despite the lack of any conclusive justification for the method. As Yule remarks, 'the student would do well to regard the method as recommended chiefly by its comparative simplicity and by the fact that it has stood the test of experience' (p.343). Having determined the regression coefficients by the method of least squares, the 'goodness' of the resulting estimates may be determined by calculating the differences between the estimated and observed values. The smaller the differences, the better the estimate. The correlation coefficient provides a means of quantifying the 'goodness' of the estimates. It can be shown that its value ranges between 1 and - 1, and that the 'goodness' of the estimate is the same whichever variable we take as given. Correlation, regression and 'common elements' For those who are still uneasy about the justification in terms of least squares, there is an alternative or supplementary interpretation of correlation and regression which is closer to Francis Galton's original conceptions and may be intuitively easier to grasp, though it does not seem to be popular with professional statisticians. If we imagine the corresponding items in the two correlated sets of variables to contain certain common elements, or to be influenced by certain common causes, then it is plausible that the degree of similarity between them should reflect the proportion of common elements or causes. Subject to certain assumptions, if the common elements account for a proportion A of all the elements of the x variable, and a proportion B of all the elements of the y variable, then the correlation between x and the common elements will be #A, the correlation between y and the common elements will be #B, and the correlation between x and y will be #(AB). If A = B, the correlation between x and y is therefore simply A. As a familiar example, full siblings on average have half their genes in common, so if their phenotypes are determined entirely by additive genes, the correlation between them is .5. Admittedly, a rigorous proof of the correlation formula based on 'common elements' requires various assumptions to be made about the size of the common elements, absence of other correlations, and so on, but purely for conceptual purposes - as a supplement to the 'least squares' approach - no great rigour is needed. The essential point is that if two variables are influenced by common causes or common elements, then we would expect their values to be related in much the same way as shown in the formal theory of correlation, without appealing to the method of least squares . In the 'common elements' approach, correlation is taken as the fundamental relationship, and regression is derivative, rather than the other way round. If we know that there is a correlation r between two sets of variables, reflecting a certain proportion of common elements, then we will expect a given deviation in one variable to be matched by some deviation in the other variable, though it will be diluted by the 'non-common' elements on both sides. So we would expect to be able to 'estimate' the value of one variable from the value of the other, in the sense that a deviation in x will correspond, on average, to a certain proportionate deviation in the y variable. This proportionate deviation will not necessarily be the same as the correlation coefficient itself. The same causes may have a greater effect on one variable than on the other, and the two variables (e.g. temperature and rainfall) may not be measured in the same units, so there could also be an arbitrary factor of scaling to be reflected in the regression coefficients. Galton's original conceptions are relevant here. Galton did not conceive of regression as a means of estimating the value of one variable from another. In the 1870s and 1880s he was trying to discover quantitative laws of biological inheritance. He noticed that offspring tended to resemble their parents, but not perfectly. If the parents were markedly different from the mean of the population, the offspring would tend to be intermediate between the parents and the population mean, or as Galton put it they would 'revert' or 'regress' towards the mean. By 1885 he had developed a procedure for measuring the regression of one variable on another, which he saw primarily as a measure of resemblance and difference based on the proportion of hereditary elements two individuals had in common. Since Galton was dealing with cases where the units of measurement and the variability of the two variables were the same, or could be easily adjusted on an ad hoc basis (e.g. by converting female heights to their male equivalents), he found his techniques sufficient for measuring resemblance. In the late 1880s Galton wanted to measure the resemblance of different parts of the body, and encountered the problem that the size and variability of different parts of the body (e.g. fingers and thighbones) may be very different. In this case the regression coefficients by themselves are not much use as a measure of resemblance. Galton hit on the solution of rescaling all the variables into units based on their own variability (in modern terms their standard deviation, though Galton used a slightly different measure). He then realised that he had discovered a principle, which he called correlation, of wider generality than his original concept of regression. Rather than seeing regression and correlation as sharply different concepts, he saw correlation as a an extension and generalisation of regression as a measure of resemblance. It was Yule, around 1900, who pioneered the modern approach which distinguishes more sharply between the two concepts. But in some ways Galton's approach may still be useful. This can be illustrated using Pearson's formulae. In most texts the close mathematical relationship between the Pearson coefficients of correlation and regression is mentioned but not really explained. The coefficient of regression of x on y is Sxy/Sy^2. But we can rescale the x and y measurements by dividing them all by their own standard deviations. Sxy/Sy^2 then becomes [S(x/sx)(y/sy)]/S[(y/sy)^2]. This can be re-arranged as [Sxy/(sx.sy)]/(Sy^2/Vy) = (Sxy/(sx.sy))/N = r_xy. In exactly the same way the regression of y on x can be rescaled, and also comes out as equal to r_xy. Thus the correlation coefficient can be interpreted in Galton's sense as a standardised regression coefficient (or the regression coefficients can be regarded as the correlation coefficient modified by differences of scale, etc), and the close mathematical relationship between the coefficients is no longer so mysterious. Note 1: Actually, this is not true unless certain further assumptions are made about the nature and distribution of errors, notably that there is no tendency for errors to go in the same direction. This is often false. The method of least squares does not eliminate the need to detect and remove any systematic sources of error. Note 2: As a simple example, suppose we have three observations, A, B, and C, of a point in 2-dimensional Euclidean space. We wish to find the 'best' estimate for the true position of the point, using the method of least squares. We therefore want to find a point P such that the sum of the squares of the distances AP, BP, and CP is minimised. First, take a Cartesian coordinate system with axes x and y, and find the coordinates of the points A, B, and C. Let us call these coordinates x'A, y'A for point A; x'B, y'B for point B; and x'C, y'C for point C. We now want to find the coordinates x'P and y'P of the required point P. Thanks to Pythagoras' Theorem, the square of a distance between two points in 2-dimensional Euclidean space is equal to the sum of the squares of the distances between the coordinates of the points along the x and y axes. Therefore the squares of the distances AP, BP, and CP are: AP^2 = (x'A - x'P)^2 + (y'A - y'P)^2 BP^2 = (x'B - x'P)^2 + (y'B - y'P)^2 CP^2 = (x'C - x'P)^2 + (y'C - y'P)^2 We need to find the values of x'P and y'P for which the total sum of these squares is minimised. Since the value chosen for x'P does not affect the value of the squares involving y'P (or vice versa), the total sum of squares will be minimised if we can minimise the sums of squares involving the x and y coordinates separately. This can be done simply by taking the mean value of x'A, x'B, and x'C as the value of x'P, and the mean value of y'A, y'B, y'C for y'P. (The mean of a set of numbers is the value that minimises the square of the 'errors', which in this case are the distances between the relevant coordinates.) The least squares estimate is therefore obtained by a simple process of averaging, and gives a point at the centre of gravity of the triangle, which seems intuitively satisfactory. The same method can easily be extended to find the best estimate for the position of a point from any number of observations in a Euclidean space with any number of dimensions. In contrast, to minimise the sum of the absolute value of the distances (in this case, to minimise AP + BP + CP), there is no simple general method. A variety of ad hoc solutions are needed, which may involve difficult geometrical problems and produce intuitively unsatisfactory results. For example, if we have a triangle with one angle greater than 120 degrees, then the vertex at that angle is itself the required point, regardless of the position of the other vertices ('Steiner's Problem'.)
Thursday, September 06, 2007
John Hawks observes that fewer people work in the agricultural sector than in services today. Around 1900 about half of Americans lived on family farms. Today around 2 percent do. If you look back two or three centuries the overwhelming majority of our ancestors would have been farmers of some sort. The fact that cities were population sinks until the 19th century also implies that the sons of the soil were the ones who inherited genetically. In A Farewell to Alms Greg Clark analyzes data which suggests that the wealthy farmer, in other words, the rural gentry, were the predominant demographic engine behind British population growth. I suspect that this is the case in many parts of the world.
What we are seeing all across the world over the last two centuries (starting in England, and now penetrating many Third World countries) is a cultural revolution. Customs, traditions and folkways which served our agricultural ancestors well now have less relevance. Many anthropologists have long claimed based on ethnographic and physical (e.g., fossil remains) grounds that the typical farmer lived more on the margins than their hunter-gatherer forebears (far less leisure time, far less protein, etc.) . In some ways today's consumer world is a second dawn after the long night of the agricultural world. Only today are the average heights in much of the world bouncing back to the norms of 10,000 years ago. In many ways I believe moderns are more like hunter-gatherers in their outlooks than agriculturalists. Institutions which arose during the period of the mass agricultural society, from our organized religions to our marriage customs (e.g., arranged marriage), have to adapt to changed times. Greg Clark reports that most of the gains in income due to increased economic efficiency have gone to unskilled laborers over the past few centuries; we live in a relatively egalitarian age in many ways. The difference in height between the poor and the rich is minimal because of a basic level of nutritional intake. Many facets of our lives, from smaller families and more transient mating patterns, also resemble the typical existence of the hunter-gatherer. During the Neolithic our species developed a number of social strategies to siphon our basic urges into forms which could result in a perpetuation of particular cultural patterns. Today the stresses and tensions (e.g., the inevitable imbalances between haves and have-nots) which gave rise to "traditional" Old World societies are less salient; but we still have a strong sentimental attachment toward these older forms (e.g., caste amongst Indian professionals) generating a new tension between the reality of free choice and the history of constraint and control. Labels: History
Wednesday, September 05, 2007
Almost a year ago, Svante Paabo's group published an article reporting a million base pairs of DNA isolated, in principle, from Neandertal bone. The results were striking, in that Neandertals appeared much closer, genetically, to humans than one might expect. Well, Nature News has an article this week about a paper in PLoS Genetics arguing that the reason for this could actually be quite parsimonious: contamination from modern humans. From the news report:
Svante Paabo, senior author of the Nature paper, concedes that his group at the Max Planck Institute for Evolutionary Anthropology in Leipzig, Germany, had problems with contamination. These prompted him to change laboratory procedures and to add controls late in 2006, after the paper was published. "I agree with [Wall's] analysis," Paabo says. "Their observations are formally correct."The paper estimates the amount of contamination at about 80%, which is pretty atrocious. The irony here, of course, is that Paabo was one of the people who made sequencing ancient DNA feasible again after fiascoes like reports of "dinosaur DNA"-- the "dinosaur" sequences ended up matching up pretty well with some of the lab members, and it appears Paabo has made the same mistake here. Fortunately, this is likely only to be a minor setback--the other group working on the DNA seems to have avoided the contamination problems, and presumably Paabo's most recent work will be more careful about it. Labels: Neandertals, Population genetics
Michael Bailey has posted a response to his critics. The first comment is from Ben Barres, who readers may remember from the women in science "controversy" of last year. The political game Barres is playing should be patently obvious-- calling into radio shows to ask pointed, misleading (and well-"framed") questions is a pretty classic polticial talk show/sports radio show tactic, and it's utterly pathetic to see it in science. Slightly depressing, even. Based on these two examples, I'm going to extrapolate and say that if you've ever got Ben Barres on your side in an argument, you've seriously fucked up and need to re-think.
Labels: politics
Underappreciated Evidence Pertaining to the Flynn Effect
posted by
Matt McIntosh @ 9/05/2007 02:01:00 PM
To my mind, the most compelling evidence in favor of Flynn Effect gains being real is physiological: it's well known that there have been increases in height concurrent with increases in intelligence in all the countries where the FE has been operative. What's less well known is that there have also been recorded increases in cranial capacity:
Standard metric data from 885 crania were used to document the changes from 1850 to 1975. Data from 19th century crania were primarily from anatomical collections, and 20th century data were available from the forensic anthropology data bank. Canonical correlation was used to obtain a linear function of cranial variables that correlates maximally with year of birth. Canonical correlations of year of birth with the linear function of cranial measurements ranged from 0.55 to 0.71, demonstrating that cranial morphology is strongly dependent on year of birth. During the 125 years under consideration, cranial vaults have become markedly higher, somewhat narrower, with narrower faces. . . . and in brain size: 7397 post-mortem records have been studied. These comphrhend all 20- to 50-year old men and women who had been autopsied in The London Hospital since 1907. Fresh brain weight, body weight and height were abstracted and analysed statistically according to sex and to year of birth, any person with a cerebral or skeletal abnormality having been excluded. Fresh brain weight in men increased gradually by an average of 0-66 g per year from a mean of 1372 g for those born in 1860 to 1424 g in 1940-a total of 52 g. The weight of the female brain increased by 0-28 g per year from 1242 g to 1265 g over the same period. Given an increase in brain size and the correlation between IQ and brain size (0.4), it'd be pretty remarkable if there wasn't any corresponding increase in intelligence. Also, in support of Lynn's nutrition hypothesis, there have been correlations found in developed countries between IQ and presence of certain micronutrients: The relationship between nutritional status and intellectual capacity in 6-year-old children was investigated in 83 subjects of medium-high socio-economic status, without any apparent risk of malnutrition and normal or high intellectual capacity. Nutritional status was evaluated by measuring food consumption, anthropometrical measurements and biochemical indicators (iron status, red cell folate and total plasma homocysteine concentration (tHcy)). IQ was evaluated using the WPPSI test. The relationship between nutritional status and IQ was investigated by multiple linear regression analysis adjusting for socio-demographic variables and sex. There was a significant and positive relationship between iron intake and both total and non-verbal IQ. This was also the case for folate intake and both total and verbal IQ. The fact that these observations were made in children from a developed country, in which their energy and education requirements are met, suggests that their cognitive development may benefit from specific preventive nutritional interventions with these nutrients. Also, there have been a few studies showing that FE gains tend to be disproportionately located at the left half of the curve rather than the right, which is the nutrition theory would predict given that the less bright people tend to be poorer and thus benefit more than the wealthier (who tend to be smarter) from nutritive improvements. Finally, from a psychometric angle, there's this paper (though I've only read the abstract) which found that the amount of covariance on test items explained by g has been decreasing as the scores have been increasing. This is what you'd expect if the biological fundamentals underlying g had been improving among the lower end of the range: when you decrease the variance of one component, item covariance attributable to other components necessarily increases. I think any satisfactory theory of the Flynn Effect has to also take these pieces of evidence into account and unify the whole picture, either explaining them or explaining them away. The only theory on the table that I think does this plausibly is the nutrition-centric hypothesis, though alternative takes are of course welcome. Labels: flynn effect
Via Steve, here is a recent lecture by James Flynn summarising his latest thinking on the Flynn Effect. (As he modestly points out, he did not coin the name.)
I have only skimmed it so far, but it seems very lucid. Includes a discussion of inbreeding effects on IQ.
Monday, September 03, 2007
Do two points make a line?
Better Memory and Neural Efficiency in Young Apolipoprotein E epsilon4 Carriers The apolipoprotein E (APOE) epsilon4 allele is the major genetic risk factor for Alzheimer's disease, but an APOE effect on memory performance and memory-related neurophysiology in young, healthy subjects is unknown. We found an association of APOE epsilon4 with better episodic memory compared with APOE epsilon2 and epsilon3 in 340 young, healthy persons. The T allele of KIBRA was found associated with better memory in a genome-wide association study last year. And now this: Age-dependent association of KIBRA genetic variation and Alzheimer's disease risk. An association between memory performance in healthy young, middle aged an elderly subjects and variability in the KIBRA gene (rs17070145) has been recently described. We analyzed this polymorphism in 391 sporadic Alzheimer's disease (AD) patients and 428 cognitively normal control subjects. The current study reveals that KIBRA (rs17070145) T allele (CT and TT genotypes) is associated with an increased risk (OR 2.89; p=0.03) for very-late-onset (after the age of 86 years) AD. I haven't done an exhaustive search, but there appears to be about four more human memory-associated genes. I wonder if they'll form a pattern. By the way, it looks like these cats Papassotiropoulos and de Quervain have the memory genome-wide association game on lock. Can someone with the right kind of knowledge take a look and see if they are doing things in a robust way? I don't really know what alternative hypotheses you have to get rid of before you can claim an association. |
  Razib's Home Page GNXP Archives Interviews Blogroll Principles of Population Genetics Genetics of Populations Molecular Evolution Quantitative Genetics Evolutionary Quantitative Genetics Evolutionary Genetics Evolution Molecular Markers, Natural History, and Evolution The Genetics of Human Populations Genetics and Analysis of Quantitative Traits Epistasis and Evolutionary Process Evolutionary Human Genetics Biometry Mathematical Models in Biology Speciation Evolutionary Genetics: Case Studies and Concepts Narrow Roads of Gene Land 1 Narrow Roads of Gene Land 2 Narrow Roads of Gene Land 3 Statistical Methods in Molecular Evolution The History and Geography of Human Genes Population Genetics and Microevolutionary Theory Population Genetics, Molecular Evolution, and the Neutral Theory Genetical Theory of Natural Selection Evolution and the Genetics of Populations Genetics and Origins of Species Tempo and Mode in Evolution Causes of Evolution Evolution The Great Human Diasporas Bones, Stones and Molecules Natural Selection and Social Theory Journey of Man Mapping Human History The Seven Daughters of Eve Evolution for Everyone Why Sex Matters Mother Nature Grooming, Gossip, and the Evolution of Language Genome R.A. Fisher, the Life of a Scientist Sewall Wright and Evolutionary Biology Origins of Theoretical Population Genetics A Reason for Everything The Ancestor's Tale Dragon Bone Hill Endless Forms Most Beautiful The Selfish Gene Adaptation and Natural Selection Nature via Nurture The Symbolic Species The Imitation Factor The Red Queen Out of Thin Air Mutants Evolutionary Dynamics The Origin of Species The Descent of Man Age of Abundance The Darwin Wars The Evolutionists The Creationists Of Moths and Men The Language Instinct How We Decide Predictably Irrational The Black Swan Fooled By Randomness Descartes' Baby Religion Explained In Gods We Trust Darwin's Cathedral A Theory of Religion The Meme Machine Synaptic Self The Mating Mind A Separate Creation The Number Sense The 10,000 Year Explosion The Math Gene Explaining Culture Origin and Evolution of Cultures Dawn of Human Culture The Origins of Virtue Prehistory of the Mind The Nurture Assumption The Moral Animal Born That Way No Two Alike Sociobiology Survival of the Prettiest The Blank Slate The g Factor The Origin Of The Mind Unto Others Defenders of the Truth The Cultural Origins of Human Cognition Before the Dawn Behavioral Genetics in the Postgenomic Era The Essential Difference Geography of Thought The Classical World The Fall of the Roman Empire The Fall of Rome History of Rome How Rome Fell The Making of a Christian Aristoracy The Rise of Western Christendom Keepers of the Keys of Heaven A History of the Byzantine State and Society Europe After Rome The Germanization of Early Medieval Christianity The Barbarian Conversion A History of Christianity God's War Infidels Fourth Crusade and the Sack of Constantinople The Sacred Chain Divided by the Faith Europe The Reformation Pursuit of Glory Albion's Seed 1848 Postwar From Plato to Nato China: A New History China in World History Genghis Khan and the Making of the Modern World Children of the Revolution When Baghdad Ruled the Muslim World The Great Arab Conquests After Tamerlane A History of Iran The Horse, the Wheel, and Language A World History Guns, Germs, and Steel The Human Web Plagues and Peoples 1491 A Concise Economic History of the World Power and Plenty A Splendid Exchange Contours of the World Economy 1-2030 AD Knowledge and the Wealth of Nations A Farewell to Alms The Ascent of Money The Great Divergence Clash of Extremes War and Peace and War Historical Dynamics The Age of Lincoln The Great Upheaval What Hath God Wrought Freedom Just Around the Corner Throes of Democracy Grand New Party A Beautiful Math When Genius Failed Catholicism and Freedom American Judaism
Archives
July 2005 August 2005 September 2005 October 2005 November 2005 December 2005 January 2006 February 2006 March 2006 April 2006 May 2006 June 2006 July 2006 August 2006 September 2006 October 2006 November 2006 December 2006 January 2007 February 2007 March 2007 April 2007 May 2007 June 2007 July 2007 August 2007 September 2007 October 2007 November 2007 December 2007 January 2008 February 2008 March 2008 April 2008 May 2008 June 2008 July 2008 August 2008 September 2008 October 2008 November 2008 December 2008 January 2009 February 2009 March 2009 April 2009 May 2009 June 2009 July 2009 August 2009 September 2009 October 2009 November 2009 December 2009 January 2010 Hello Movable Type archives August 11,2002 August 18,2002 August 25,2002 September 01,2002 September 15,2002 October 20,2002 December 08,2002 December 22,2002 December 29,2002 January 05,2003 January 12,2003 January 19,2003 January 26,2003 February 02,2003 February 09,2003 February 16,2003 February 23,2003 March 02,2003 March 09,2003 March 16,2003 March 23,2003 March 30,2003 April 06,2003 April 13,2003 April 20,2003 April 27,2003 May 04,2003 May 11,2003 May 18,2003 May 25,2003 June 01,2003 June 08,2003 June 15,2003 June 22,2003 June 29,2003 July 06,2003 July 13,2003 July 20,2003 July 27,2003 August 03,2003 August 10,2003 August 17,2003 August 24,2003 August 31,2003 September 07,2003 September 14,2003 September 21,2003 September 28,2003 October 05,2003 October 12,2003 October 19,2003 October 26,2003 November 02,2003 November 09,2003 November 16,2003 November 23,2003 November 30,2003 December 07,2003 December 14,2003 December 21,2003 December 28,2003 January 04,2004 January 11,2004 January 18,2004 January 25,2004 February 01,2004 February 08,2004 February 15,2004 February 22,2004 February 29,2004 March 07,2004 March 14,2004 March 21,2004 March 28,2004 April 04,2004 April 11,2004 April 18,2004 April 25,2004 May 02,2004 May 09,2004 May 16,2004 May 23,2004 May 30,2004 June 06,2004 June 13,2004 June 20,2004 June 27,2004 July 04,2004 July 11,2004 July 18,2004 July 25,2004 August 01,2004 August 08,2004 August 15,2004 August 22,2004 August 29,2004 September 05,2004 September 12,2004 September 19,2004 September 26,2004 October 03,2004 October 10,2004 October 17,2004 October 24,2004 October 31,2004 November 07,2004 November 14,2004 November 21,2004 November 28,2004 December 05,2004 December 12,2004 December 19,2004 December 26,2004 January 02,2005 January 09,2005 January 16,2005 January 23,2005 January 30,2005 February 06,2005 February 13,2005 February 20,2005 February 27,2005 March 06,2005 March 13,2005 March 20,2005 March 27,2005 April 03,2005 April 10,2005 April 17,2005 April 24,2005 May 01,2005 May 08,2005 May 15,2005 May 22,2005 May 29,2005 June 05,2005 June 12,2005 June 19,2005 June 26,2005 July 03,2005 July 17,2005 August 07,2005 Blogspot archives June 2002 July 2002 August 2002 September 2002 October 2002 November 2002 December 2002
10 questions for....
Parag Khanna James Flynn Jon Entine Gregory Clark György Buzsáki Heather Mac Donald Bruce Lahn A.W.F. Edwards Luigi Luca Cavalli-Sforza Joseph LeDoux Matthew Stewart Charles Murray James F. Crow Adam K. Webb Justin L. Barrett David Haig Judith Rich Harris Ken Miller Dan Sperber Warren Treadgold Armand M. Leroi John Derbyshire
Blogs
The GiveWell Blog Your Religion Is False Colby Cosh Steve Hsu Audacious Epigone Catallaxy Files Inductivist 2 Blowhards Genetic Future Agnostic Steve Sailer Dienekes Derek Lowe Razib Khan Razib at Comment is Free Secular Right Glenn Reynolds Jim Miller Kevin McGrew John Hawks Peter Fost Randall Parker Less Wrong Charles Murray Carl Zimmer EconLog Marginal Revolution
Principles of Population Genetics
Genetics of Populations Molecular Evolution Quantitative Genetics Evolutionary Quantitative Genetics Evolutionary Genetics Evolution Molecular Markers, Natural History, and Evolution The Genetics of Human Populations Genetics and Analysis of Quantitative Traits Epistasis and Evolutionary Process Evolutionary Human Genetics Biometry Mathematical Models in Biology Speciation Evolutionary Genetics: Case Studies and Concepts Narrow Roads of Gene Land 1 Narrow Roads of Gene Land 2 Narrow Roads of Gene Land 3 Statistical Methods in Molecular Evolution The History and Geography of Human Genes Population Genetics and Microevolutionary Theory Population Genetics, Molecular Evolution, and the Neutral Theory Genetical Theory of Natural Selection Evolution and the Genetics of Populations Genetics and Origins of Species Tempo and Mode in Evolution Causes of Evolution Evolution The Great Human Diasporas Bones, Stones and Molecules Natural Selection and Social Theory Journey of Man Mapping Human History The Seven Daughters of Eve Evolution for Everyone Why Sex Matters Mother Nature Grooming, Gossip, and the Evolution of Language Genome R.A. Fisher, the Life of a Scientist Sewall Wright and Evolutionary Biology Origins of Theoretical Population Genetics A Reason for Everything The Ancestor's Tale Dragon Bone Hill Endless Forms Most Beautiful The Selfish Gene Adaptation and Natural Selection Nature via Nurture The Symbolic Species The Imitation Factor The Red Queen Out of Thin Air Mutants Evolutionary Dynamics The Origin of Species The Descent of Man Age of Abundance The Darwin Wars The Evolutionists The Creationists Of Moths and Men The Language Instinct How We Decide Predictably Irrational The Black Swan Fooled By Randomness Descartes' Baby Religion Explained In Gods We Trust Darwin's Cathedral A Theory of Religion The Meme Machine Synaptic Self The Mating Mind A Separate Creation The Number Sense The 10,000 Year Explosion The Math Gene Explaining Culture Origin and Evolution of Cultures Dawn of Human Culture The Origins of Virtue Prehistory of the Mind The Nurture Assumption The Moral Animal Born That Way No Two Alike Sociobiology Survival of the Prettiest The Blank Slate The g Factor The Origin Of The Mind Unto Others Defenders of the Truth The Cultural Origins of Human Cognition Before the Dawn Behavioral Genetics in the Postgenomic Era The Essential Difference Geography of Thought The Classical World The Fall of the Roman Empire The Fall of Rome History of Rome How Rome Fell The Making of a Christian Aristoracy The Rise of Western Christendom Keepers of the Keys of Heaven A History of the Byzantine State and Society Europe After Rome The Germanization of Early Medieval Christianity The Barbarian Conversion A History of Christianity God's War Infidels Fourth Crusade and the Sack of Constantinople The Sacred Chain Divided by the Faith Europe The Reformation Pursuit of Glory Albion's Seed 1848 Postwar From Plato to Nato China: A New History China in World History Genghis Khan and the Making of the Modern World Children of the Revolution When Baghdad Ruled the Muslim World The Great Arab Conquests After Tamerlane A History of Iran The Horse, the Wheel, and Language A World History Guns, Germs, and Steel The Human Web Plagues and Peoples 1491 A Concise Economic History of the World Power and Plenty A Splendid Exchange Contours of the World Economy 1-2030 AD Knowledge and the Wealth of Nations A Farewell to Alms The Ascent of Money The Great Divergence Clash of Extremes War and Peace and War Historical Dynamics The Age of Lincoln The Great Upheaval What Hath God Wrought Freedom Just Around the Corner Throes of Democracy Grand New Party A Beautiful Math When Genius Failed Catholicism and Freedom American Judaism   Policies Terms of use © http://www.gnxp.com Razib's total feed: |

{kind=link}